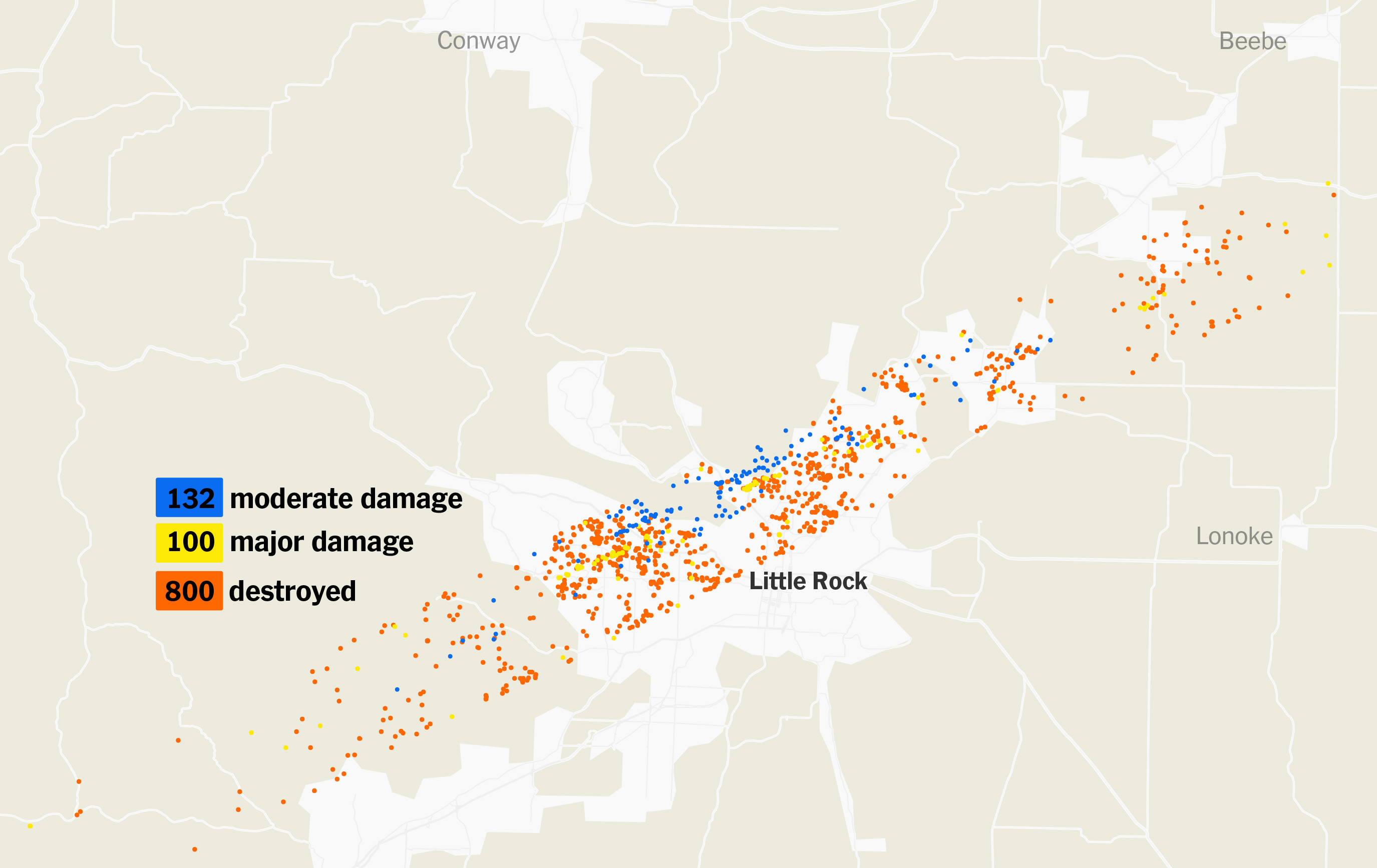
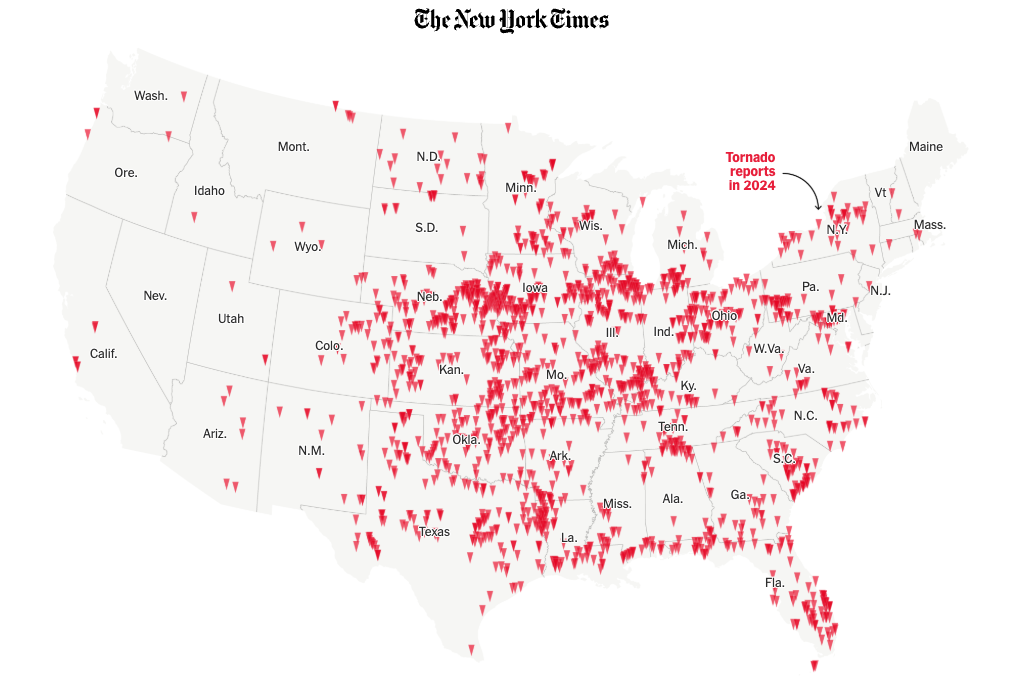
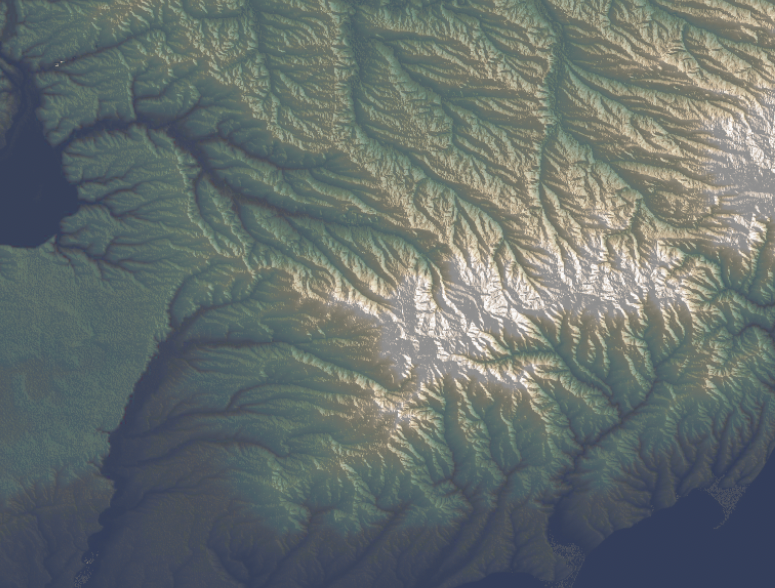
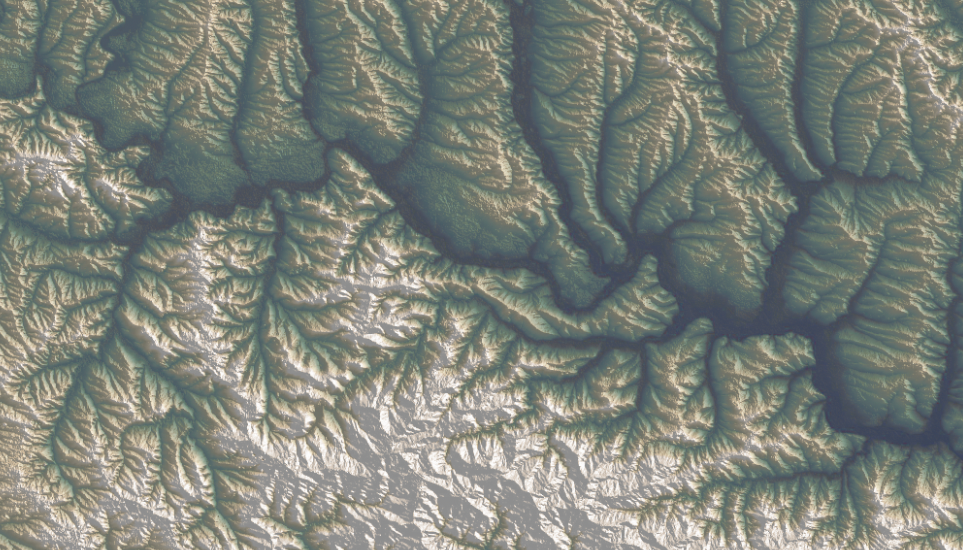
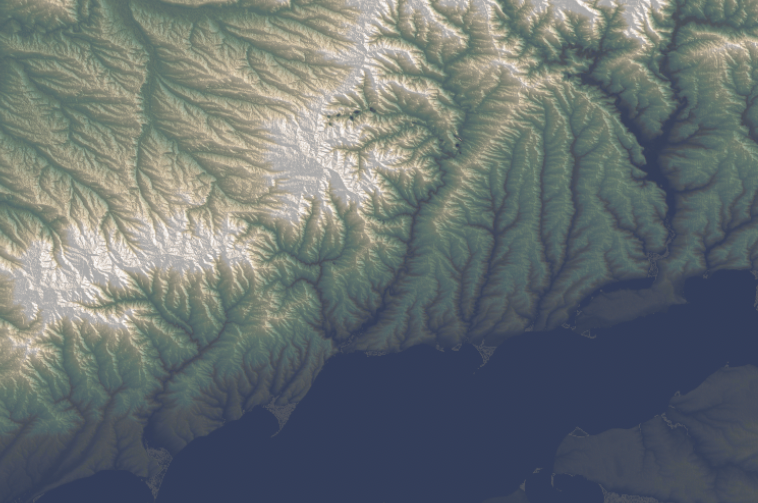
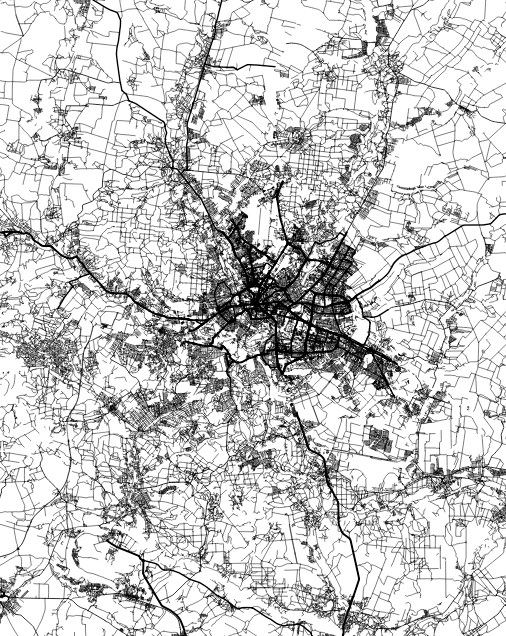
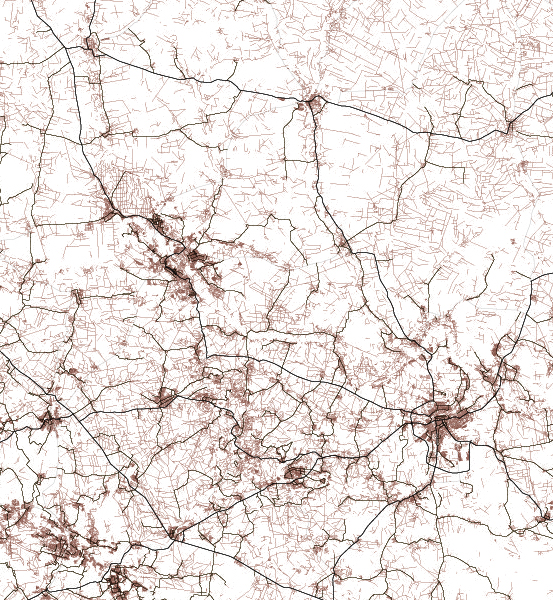
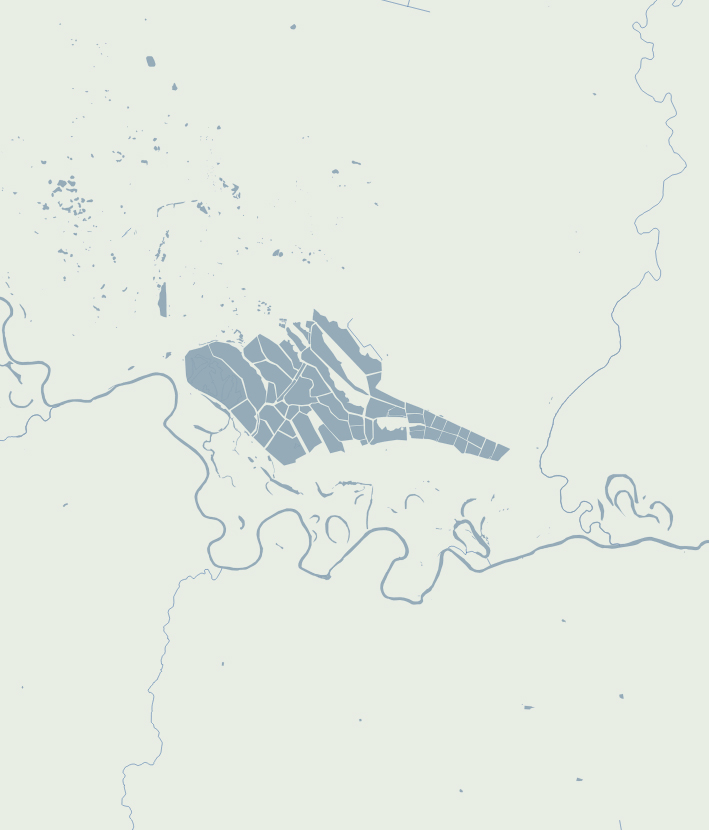
A while ago I started to look at the API of a company that does high res aerial imagery overlapped with FEMA’s damage reports. Truly it’s a great and detailed resource, here’s an example of the data, each dot here is a building classified by FEMA after a weather disaster, in this case a 2023 tornado in Little Rock, AR:
Data sample from VEXCEL API.
My original idea was to putt together all the destruction in 2024 across the US. And to some extent, I managed to extract all the information and create some visualizations that look like pages from a book written in an ancient language. Below is an unpublished piece with buildings damaged throughout 2024 by natural disasters such as hurricanes, fires and tornadoes, the area in detail is the just the ones affected by 2024’s hurricane Helene:
A detail of the non-published piece “footprints of damage”
The abstraction of taking footprints out of the map was a fun idea, I think that shape allows you to see beyond the location, you can compare buildings, some states show larger damaged buildings, others are super tiny, also you can notice that there are places with larger clusters of damage due to certain events, works well to show scale of damage, but it’s a quite deep graphic with many layers of information.
I learned a lot from this project, for example I printed out SVG maps with the building footprint by county. But the dilemma was how to take each polygon and reposition it into line-blocks without changing the scale… That to thousands of polygons in different files. Python and js helped me out to read each of the 73 maps I got and align groups of buildings into these blocks.
I wrote my own script using svg.js, then a colleague sent me over this other nice way to re-arrange svg shapes using SVGnest, so fun! maybe this can help you if you are trying to achieve something similar.
An example of SVGnest.
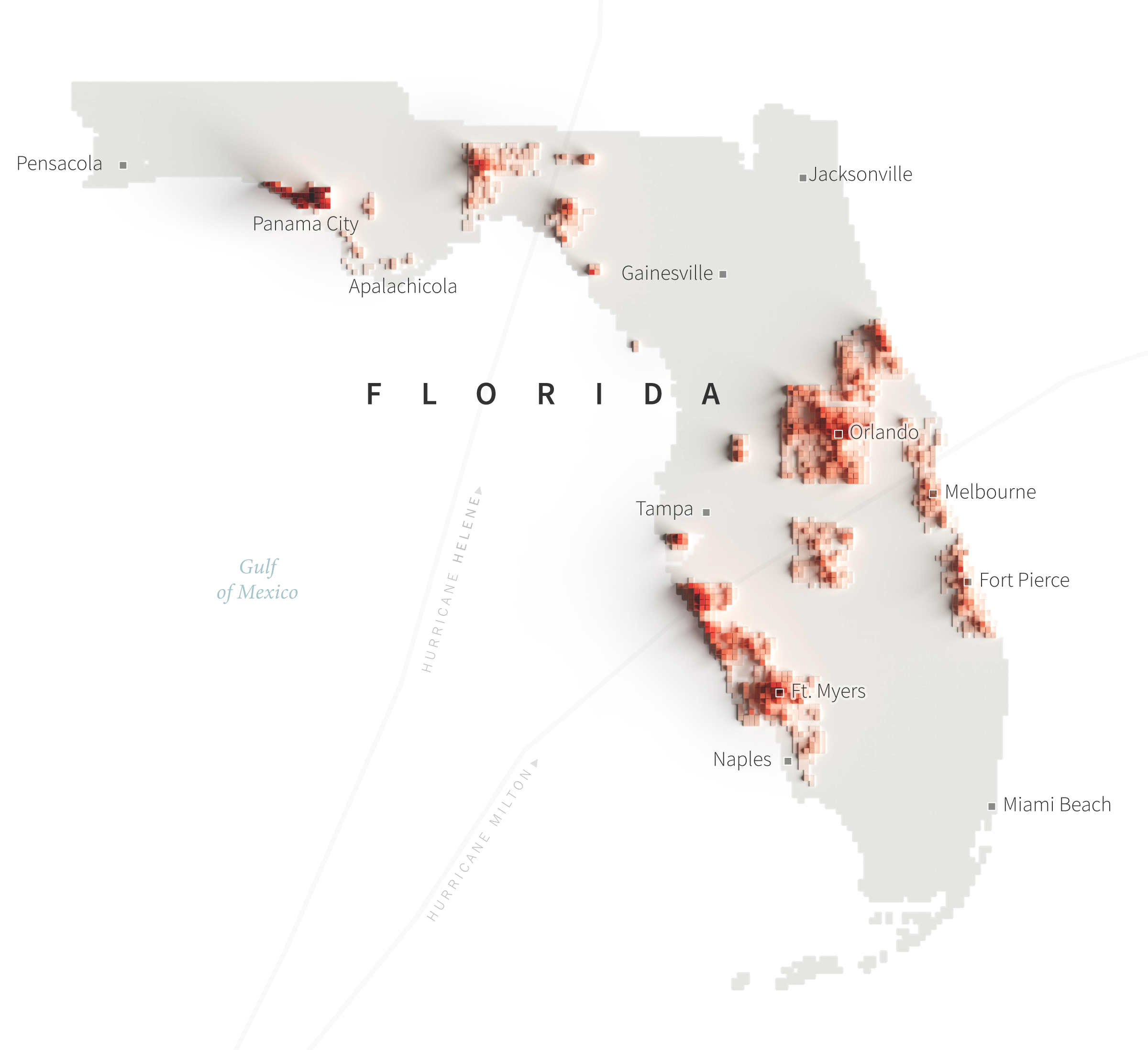
However, looking at where all that happened is interesting, so I did a series of state maps to visualize clusters of damage. I created grids of 5km and counted how many buildings fall into each quadrant using one of the point analysis tools in QGIS. Then I took the result to blender to create one map per state like the one of Florida below.
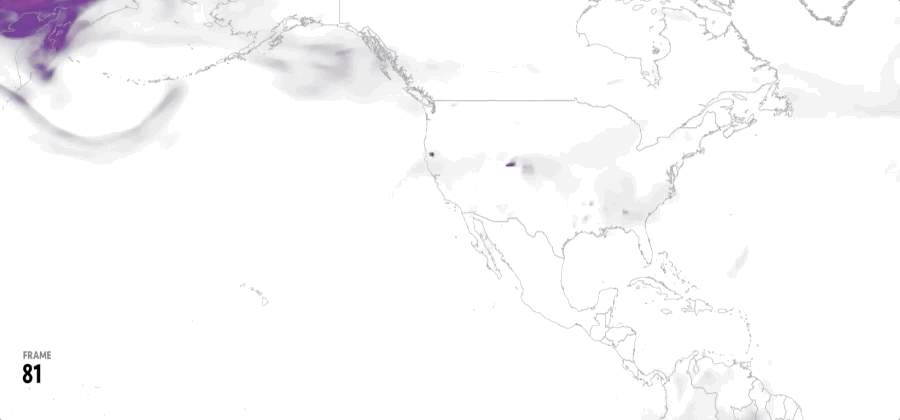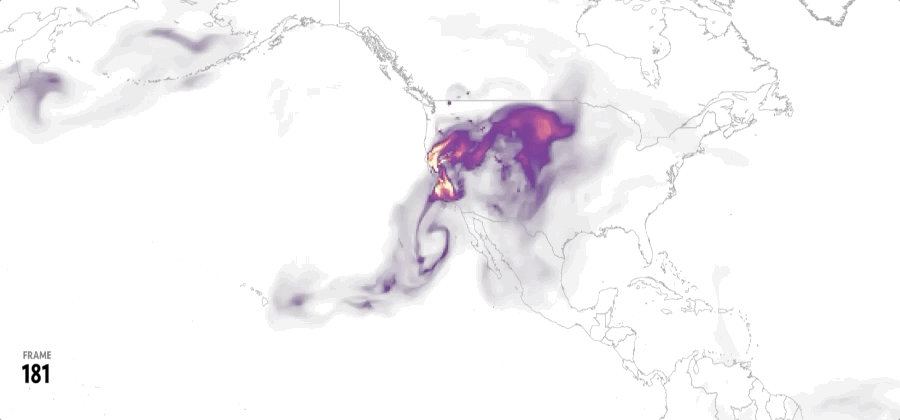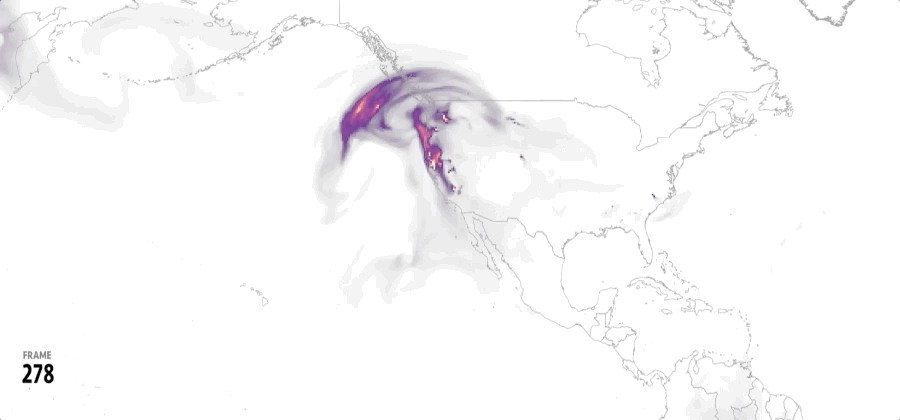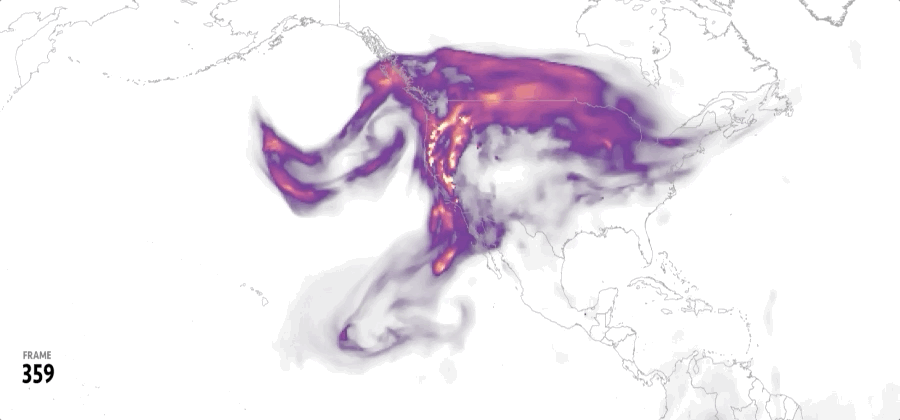
The animation showed one of these maps per state while counting the cumulative number of damaged buildings each time a new state was added until each record for 2024 was complete. That for +57,000 footprints.
Focus shift
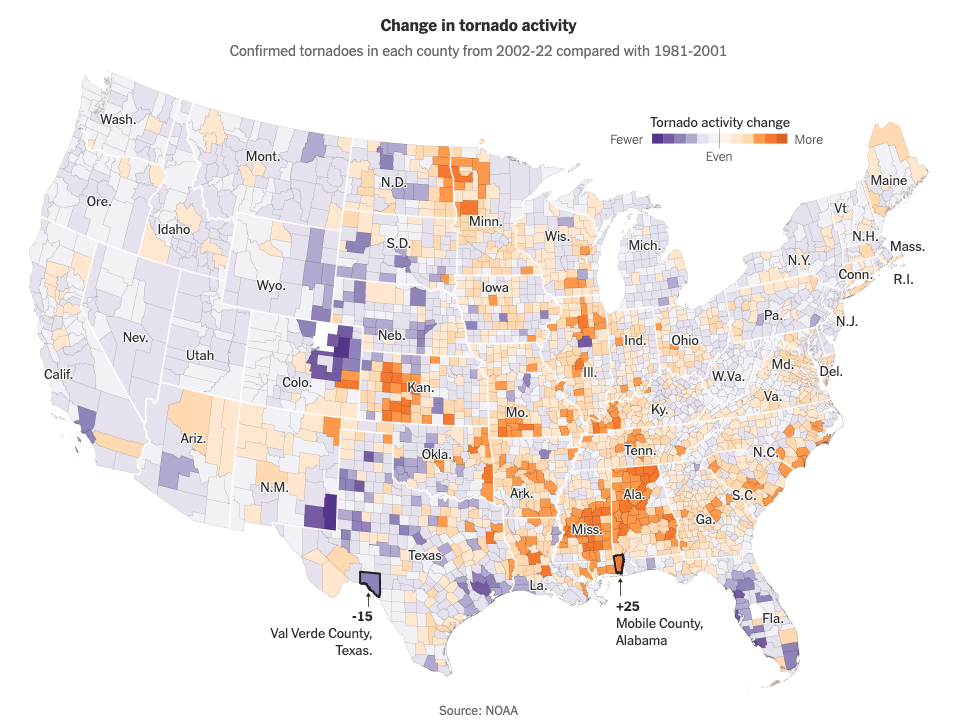
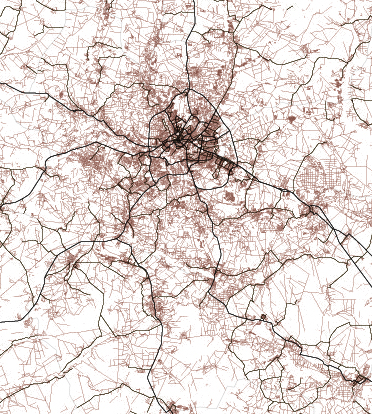
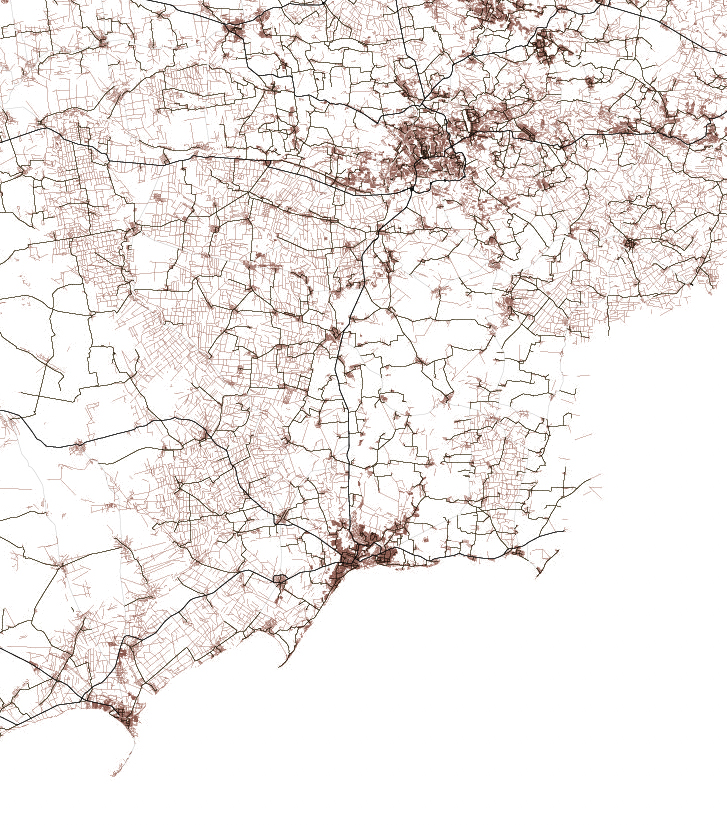
In a turn, I found that 2024 was a very active year for tornadoes, I did some interviews to researchers in different universities and found out more and more interesting data on these events, so the story went from mapping damage across the US to report on how intense the tornado season was in 2024.
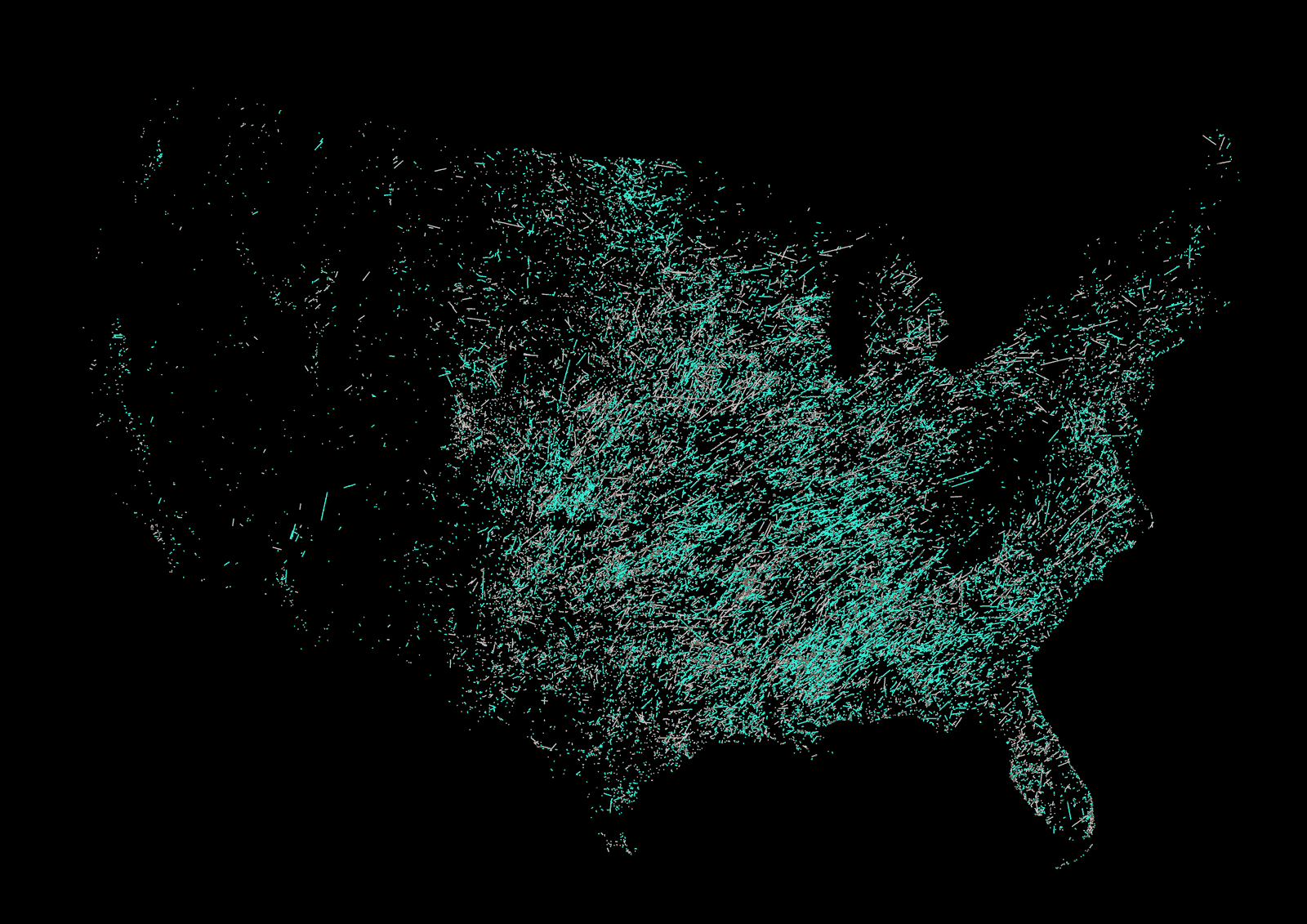
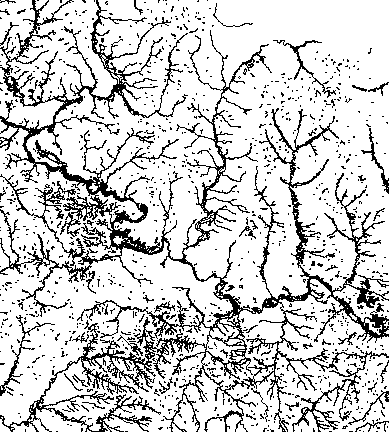
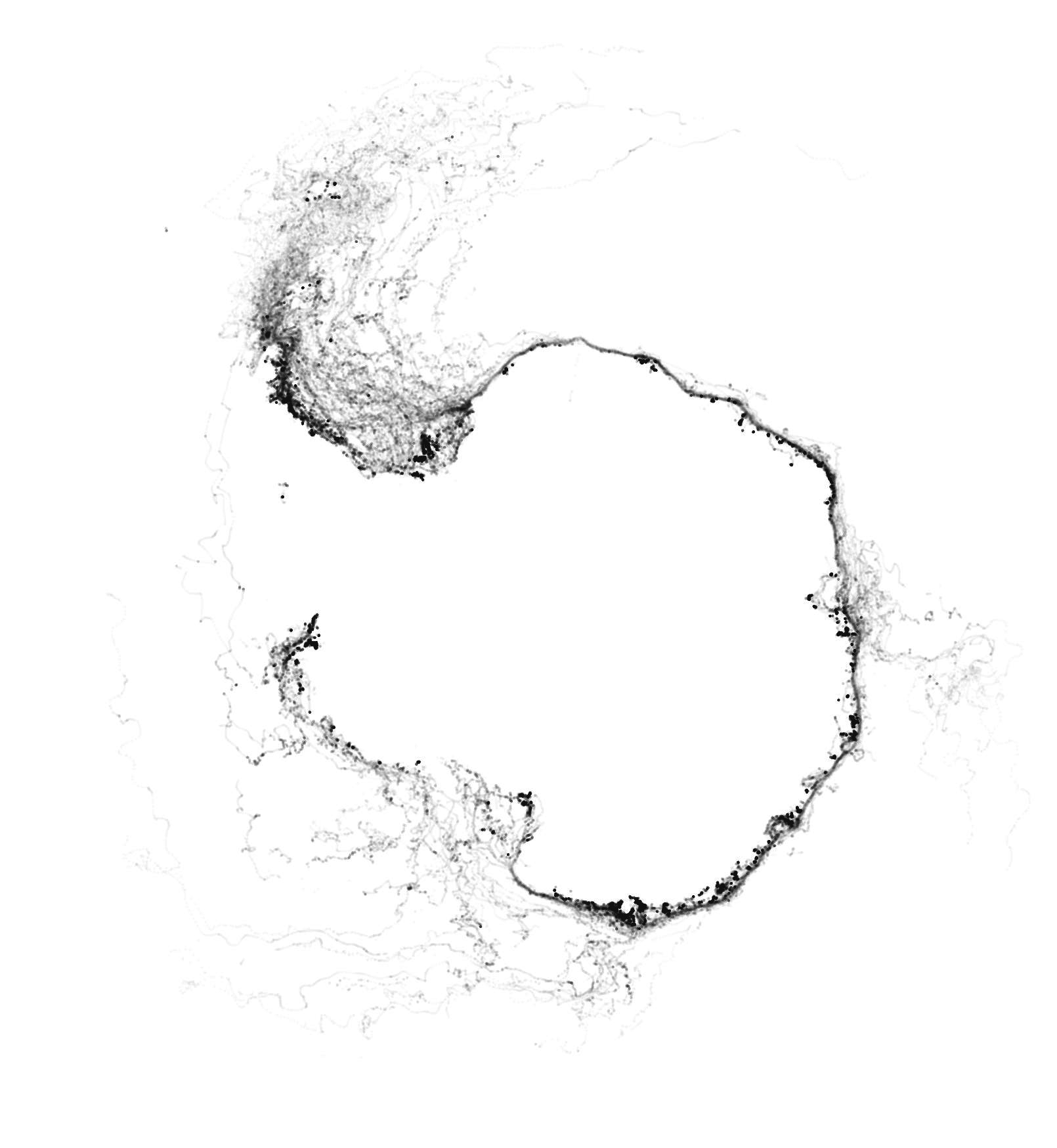
All tornado tracks in the US between 1980 and 2023. Based on data from NOAA. (Green the most recent 20 years, gray the oldest. Same data as the one at the top of this article but in single shot.
I did used a little fraction of the footprints I prepared for the original story, but I guess this reflects how sometimes the stories can evolve into something else, talking to people might make you realize that there’s another interesting angle of things.
You can read more about the company providing the data for footprints and HD imagery on the tornado story I published at the Times here: [ UNLOCKED STORY LINK ]
A screenshot of the published page at the NY Times, Dec. 2024.A screenshot of the published page at the NY Times, Dec. 2024.
Tornadoes turned out to be super interesting, there a lot of caveats on this data from NOAA, the CDC, FEMA and the private company doing the imagery. I guess my infofail here was spending too much time trying to map every damaged building in the U.S.
Digging into the data a little more and talking to experts can save you time and maybe, as it did for me, even give you a new perspective on a story you want to tell.
About infofails post series: I believe that failure is more important than success. One doesn’t try to fail as a goal, but by embracing failure I have learned a lot in my quest to do something different. My infofails are a compendium of graphics that are never formally published by any media. These are perhaps many versions of a single graphic or some floating ideas that never landed.
In short, infofails are the result of my creative process and extensive failures at work.
Are you liking infofails?, have a look to previous ones:
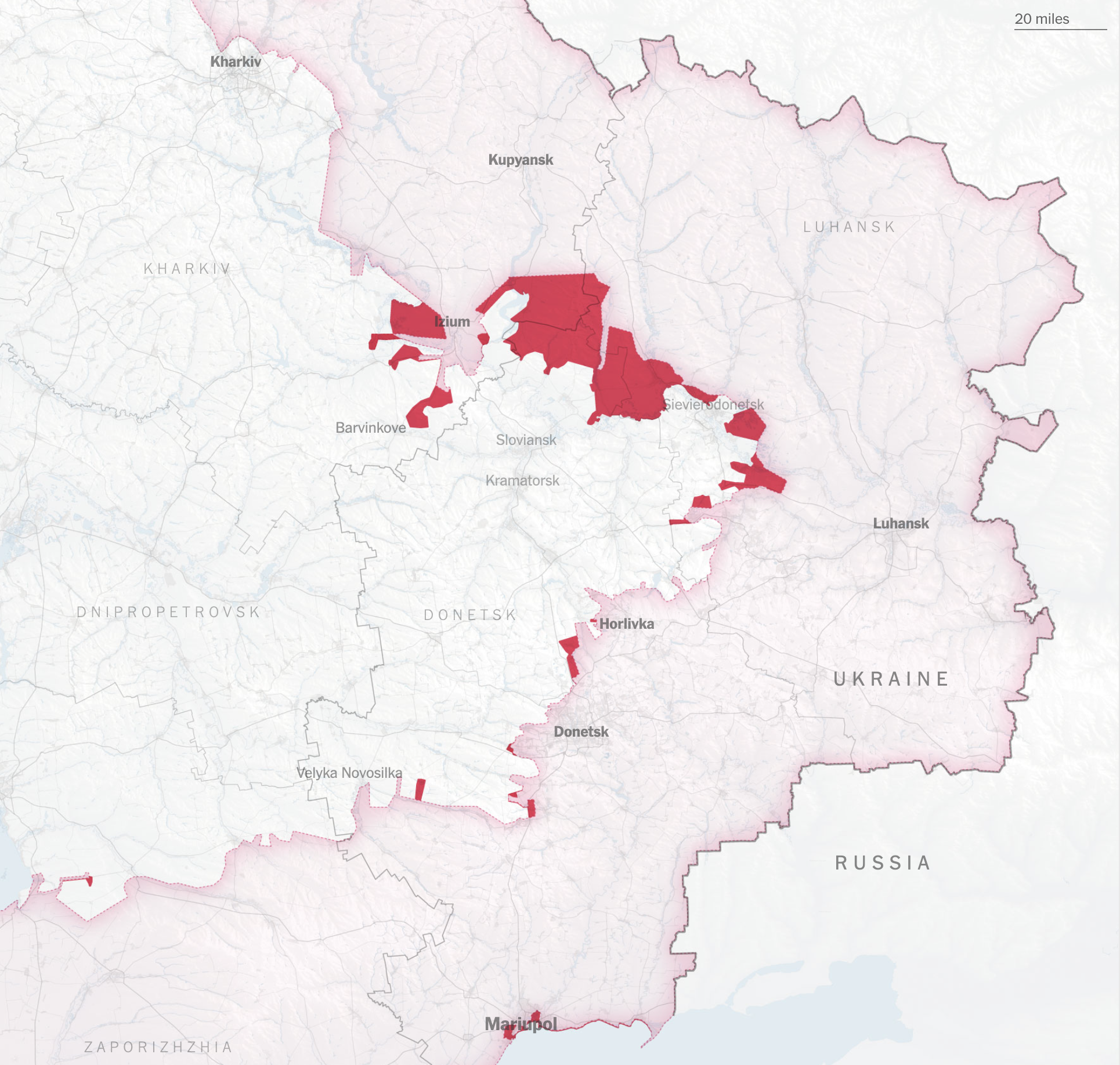
In June 2022, with a very basic understanding of the SAR technology, I started to use Sentinel-1 data to report on the progression of damage in Ukraine. Shortly after, Tim Wallace, our Editor for Geography connected me with Oregon State University, Jamon Van Den Hoek and City University of New York, Corey Scher, two leading researchers in the field of InSar sensing. They have been using this technology for a long time and were also exploring its use in Ukraine shortly after the beginning of the war. They have also help us to analyze the development of destruction in Gaza more recently.
Corey and Jamon help us to process terabytes of data to flag areas where structural changes happened. The first rounds were a challenge, the data is so sensitive that it was influenced by things like vegetation, soil conditions and snow. Things like mining activity, construction areas and train stations represented a challenge too.
A mine in Poltava. Red marks flag changes happening in the surface. BASE IMG BY PLANET LABS.A port area in Odesa, red flags showed up probably due to vegetation and the moving shipping containers. IMG BY PLANET LABS.
Somehow we needed to filter out all of those things. I was doing a roll of analyst testing the data the researchers provide with HD satellite images. I spent weeks looking at the areas flagged to find things that maybe interesting to highlight later, but I also encountered weird stuff, which is normal in early stages of data analysis.
The image below is an screenshot of one of the many QGIS files I created to explore things in different ways, the rectangles there are areas I flagged for myself to follow closer.
While exploring the data, I also noticed these long straight lines, which seemed to be the data tiles overlapping or something.
Looking down from space
I used QGIS, the Planet explorer, Maxar imagery and Google earth to crosscheck the data and be sure we were pointing at real damage related to the war and not something else.
Hundreds of buildings destroyed block after block after the battle for Mariupol, this is a detail of one of those blocks. IMG BY MAXAR, May 2022.
Every corner of the country had its own story to tell, some bettern known like the case of Mariupol, but during my exploration I learned about many places I had never heard of before, many villages that were destroyed far from the media spotlight.
A destroyed school in Izium. IMG BY PLANET LABS, March 2022.
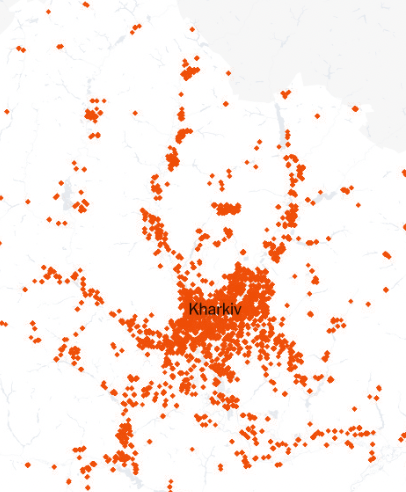
In the satellite image below, the town of Kamyanka, in Kharkiv, shows the remains of what were once homes. When you look closely, you can notice the multiple craters, presumably caused by explosions.
IMG BY MAXAR VIA GOOGLE EARTH. March 2022.
Google has being updating imagery in Ukraine, this is one of those places you can easily see with Google Earth. As I’m writing this post the buildings are still in ruins accordingly to the image from August 29, 2022.
Damaged buildings… but what type: houses? stores? military?
I used OpenStreetMap to identify some of the damaged buildings, however, even tho OSM has a lot of good data, I needed more to fill the gaps.
Around June 2023, Microsoft Bing released a great data set of millions of structures in Ukraine, so I merged it with my existing OSM records, and ended up processing +17 million of building footprints. But it was also a nightmare, I tried to use Google Cloud and a few more things to get overlapping records with the damage flags, short story… all collapsed. –I probably set it up all wrong.
Finally I found a quicker way using a script python, reducing the time of cross check from weeks to a few hours running the code in my laptop overnight.
After overcoming that hurdle, I began collecting evidence of sensitive damaged locations.
I first identified schools, but I accumulated hundreds of these images for hospitals and churches too.
New data sets were back and forth, from that first version to a better, more precise and clearer one including additional months of data. Meanwhile I was going through hundreds of photos, fighting and shelling reports and other damaged related information. We accumulated so much data since the war started that it took me weeks to classify all of it and get a better sense of the mayor events happening in different cities.
Photos from our correspondents in the ground and wire providers also provided dates and places to confirm damaged records in certain locations.
I also explored social media for evidence of damage, like this footage of a warehouse in Partyzanske in Mykolaiv Oblast, media by Мужской Клуб Донбасса via Telegram here: https://t.me/donbass_mens_club/3691
A dosage of ‘infofails’
If you have read my blog before, you know what an infofail is. But just in case, I tend to save pretty much all the stuff I do, even if it’s just for my own understanding of the information. Here’s a little of a wonderful date set I spent a lot of time in, but we left out of the project.
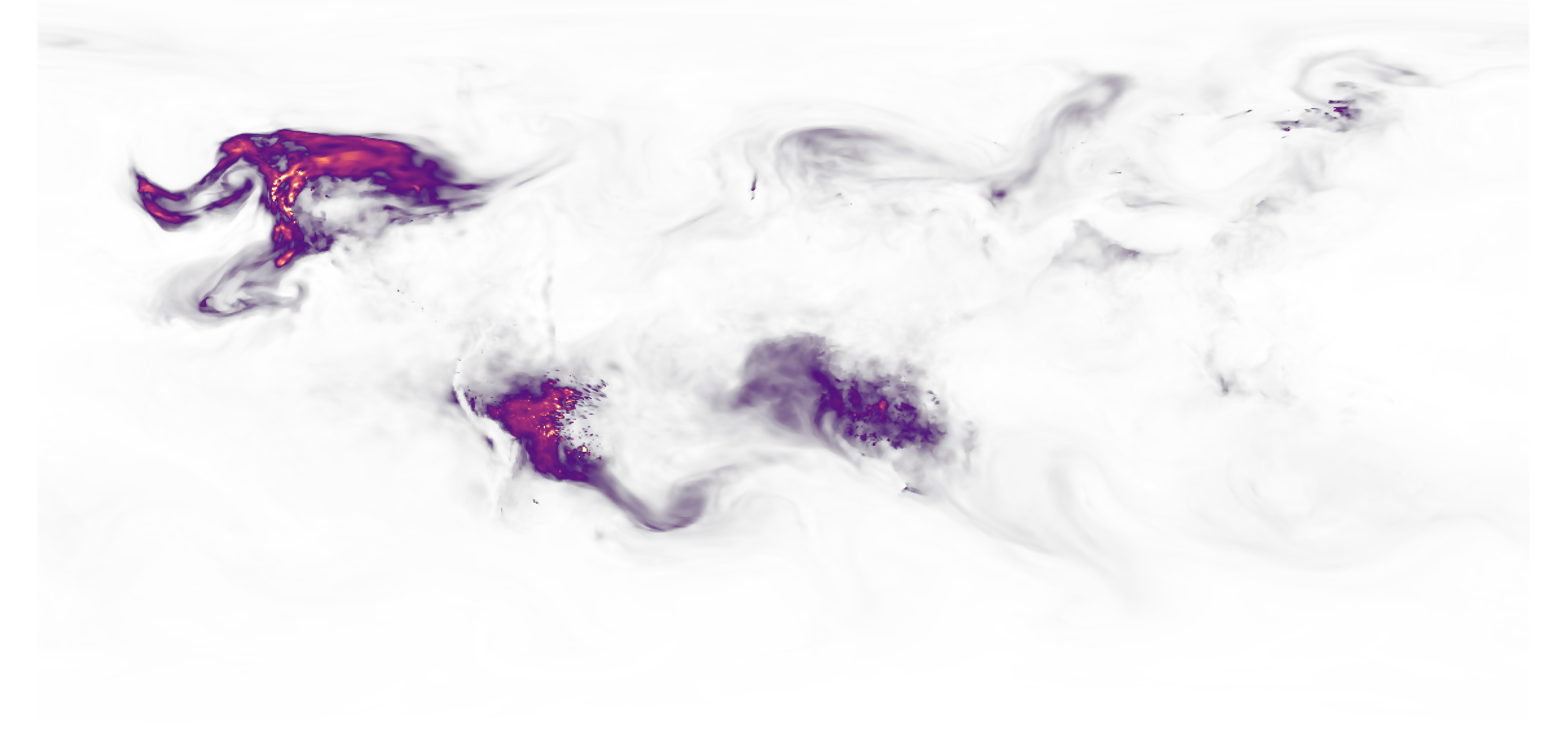
I did a lot of sketches to understand the data we have from fires, some seemed to align to the front lines after plotting the data like in the image below showing clusters of fire detections in a year.
Fire detections from various satellites clustered in grid cells, the darker the cell the more fires registered. Front lines data via ISW.
As I mentioned, we abandoned this data for editing reasons, but also because some months showed some sort of alignment with war events, and others just weren’t very clear. One idea I have was to use the large amount of photos we have showing explosions/fire in certain locations where the satellite also picked up a thermal signature.
I also rendered a 2022 country wide “calendar of fires” (see below), there’s one row per month, taller and warmer colors represent more fire activity, some months match intense battles around the country, unfortunately other seasonal fires were also blended in the data.
From a csv file with values of thermal detections, rendered in Blender.
In the image above, January is at top, note the 3rd line were the columns are taller and warmer. That matches when Russia launched its full scale offensive over Ukraine.
But the data also slightly varies by region, so I also did 2d graphics looking a different locations, including a few more data and in different sorting of time.
Sketching data
As time went on, I continued sketching maps and other visualizations for this project. This was not full-time dedication, while working on this project, I published 17 other projects and explored about 15 more that led to nothing or are still in progress. So I had to do quick and easy things to distribute my efforts. But let’s take a look to those quick sketches.
Part of my process is to annotate screenshots, just to remember things later. Below is an area of Kharkiv, highlights in red are buildings damaged during the first months of the war in 2022.
This probably turns out to be obvious, but I found it quite interesting to see how in the first versions of the damage data some patterns emerged, the damage followed the roads leading to the cities. Can you see the lines too?
Damage over the city of Kryvyi Rih in Dnipropetrovsk Oblast.Damage over the city of Kharkiv.
I spent long hours just exploring the map, turning layers on and off, adding before and after HD images, making things jump off my screen. Most of the exploring was made using Felt, Google Earth, Google spreadsheets and QGIS, screenshots and annotations on photoshop by copy+paste portions of my screen.
I did a lot of maps reporting on different of battles in other stories, so, some places seemed more familiar to me. Somehow the shape of the damage logs matched what I saw before, and that was a relief.
But also, other things, where it seems like the data tells a story that I can’t confirm. In the timelapse below, using the ISW control areas, you can see how perhaps Ukrainian troops tried to take this city, as the front lines move away, the records also cease.
Areas of control by ISW.
Ukraine has a huge territory, so I identified regions to look closer, sometimes because the change over time was interesting, or because the amount of damage registered. I guess my interest was too wide, I selected almost half of Ukraine, these are some quadrants I was interested in explore deeper:
Just to be clear, explore deeper mean I went on looking for more images, reading reports and blogs about what happened there… It took me months, but I did explore all of them.
I also did some sketches using 2d geometries based in the totals of area damaged per settlement.
Damage around Kyiv
The are of Dnipro and Zaporizhzhia
The area of Kherson
I also sketched some of cities data through time using photoshop:
Then modeled in blender using an early version of the data, just to get a sense of a few cities and how they compare to each other. Note the colors are key in time, older records are cold (blues) while more recent are warmer.
Modeling data
We also tested some building height data, following the idea of full 3D transitions from the photos we had of the Marinka town where we focused our story.
Transitioning concept from drone footage, to the city 3D model, to a satellite image.
We changed the top sequence a few times, but it was always focused over Marinka. The concept was to look close to a building with meaning to the residents, then scale to a street, to the town, to the region, to the country. That setting up to the reader the scale of data we analyzed.
Early concept to show damage recorded in Marinka
Here you have some of the first demos I did using the data on a larger area to eventually move the camera far enough to see the whole country.
Workflow
To get you an idea of my workflow, I started with a set of geotiffs, shapefiles and geojsons. We applied some python to filer the data and focus on the things we wanted, clustering data in different resolutions, then added all into QGIS to export tiff layers out. I used one black and white file for each feature, one for water, one for land, one for how high each polygon should be, one for color highlights and so on.
I like to use QGIS to wrap-up everything, but I feel better styling the data in photoshop, so some of the work in styles was done there, mostly color using the black/white tiffs as a mask over solid layers.
Then I exported a layer out of photoshop with colors and overall styles, plus one more with the elevation data matching the same crop from the original QGIS outputs.
Those tiffs went to blender to be rendered as 3d objects.
From blender, I moved all to After Effects. There is handled the timing, labels and transitions, a custom built script takes each layer and exports a single json file for the web component. The file includes the basic properties as position, styles and timing. The svelte component takes that and arranges the assets depending on what device you are watching on.
I tested a few different set ups changing styles and clustering, here’s one of those versions with a flight-over camera.
I did a few versions more just to find the one that feels right. Sometimes happy accidents happened like this inverted render, which is nice but not the thing I was looking for:
some more versions…
and versions…
Binary maps and storage
Many more versions later, I did a series of custom cities showing only buildings colored by damage as true/false. Red is damaged, by this point we were in the version 40 of the data, 1 terabyte of maps, photos, videos, scripts and many other assets. I bought an external drive for this project, every time I was going to move files I left my laptop running for a day or two to make sure I didn’t lose anything.
Damage in Bakhmut
Damage in Mariupol
Damage in Sieverodonetsk
Damage in Rubizhne
Damage in Kherson
Damage in Tsiurupynsk
Zaporitzhzhya
Damage in Odesa
But that was just a little portion of the data we used. Corey and Jamon, the researchers you meet at the top of the long page, accumulated more than 50 times more data than me to get the right data set for this article.
Around +40 versions later, we landed in the definitive data set.
Introducing the story for readers
The story was almost there, but some small tweaks here and there, mostly in the copy side and technical descriptions, but there was yet one more thing to take care about, and that was explaining and introducing this to our readers in the home page.
I prepared still images and animations for this purpose, the video colleagues also help me prepare a reel that would be shown on the main page and on social networks. Basically me talking about the project, you can see the final version of it at The New York Times instagram account here.
Preparing the print
We usually go first on the web, then on print. So that means after we hit the publish button, I started to plan the pages for the print edition with a different team. Even tho we are using the same story as base line, the way of presenting things is different, new pieces should be produced taking into consideration the requirements of paper.
The process was sort of similar, first preparing assets in QGIS, render out black and white .tifs to be later used as color mask in photoshop, then merged in a color layer plus a black and white layer with the heights data baked in. Then those 2 layers went to blender to get the final base map. Annotations and other small details were done in Adobe Illustrator.
Blender setup for print.
A few different versions went around, because we move it to the front page, some small charts of context were dropped off. Here some of those early testing versions, some even with a few errors:
The print edition was published today (June 22, 2024) on a special format displaying the large map and a few more pages inside wrapping up the whole story with adaptations of the original content. The print team did an exceptional work, they have a lot of experience in getting the best version for the readers out there.
I started exploring this project in June 2022, and today, two years later, I find myself reading the last piece of the project finally published, there’s a sense of relief to know that I fulfilled the mission of reporting on this very relevant topic with such a display for the New York Times.
Thanks for reading, and don’t forget to buy this special edition of the paper.
At some point in 2022, I was collecting information about Taiwan and its national identity. Among many, I read some articles like this one and documented records about their increasing drive to identify themselves as Taiwanese and progressively distance themselves from the Chinese. The subject is very deep and tangled, I’m not going to pretend to understand it, but in short, Taiwan’s heritage is deeply tied to the mainland (PRC), and blends with many other influences from its diverse past. In such a way, its particular conditions have created some interesting things that have taken root in the simplest things of everyday life.
One of those things that any one can see on the streets is food. Not only its dishes that have evolved and conquered the world like the yummy Bubble Tea, but the simplest things like how the business are tagging their restaurants in food delivery platforms.
Uber Eats and Foodpanda use labels to make it easier to find what you’re looking for, just like any other platform you might be familiar with. In those “categories” you can find Japanese, American, Chinese, Thai, Taiwanese… I’m sure you know how it works, but just in case here’s a screenshot of what I mean:
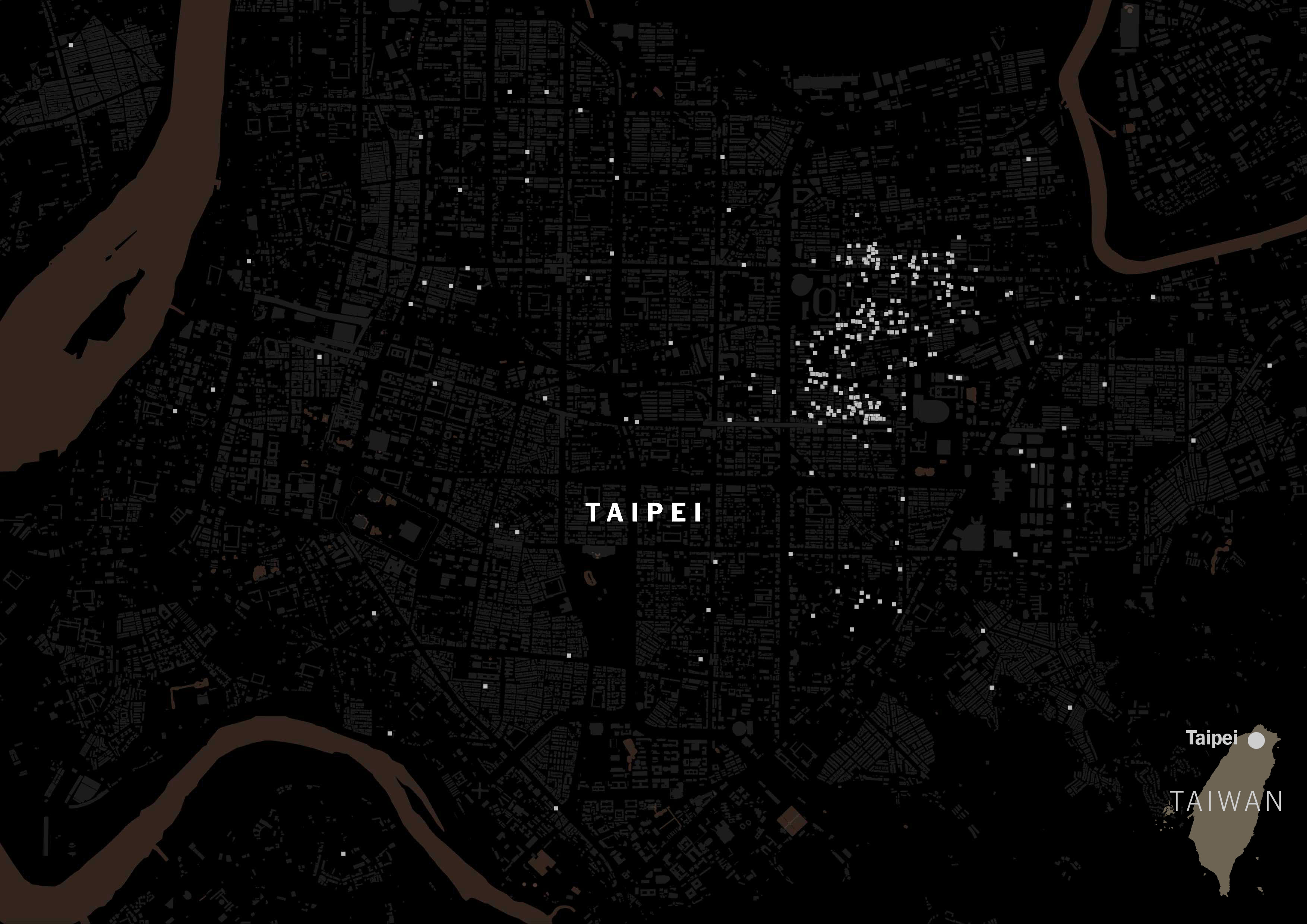
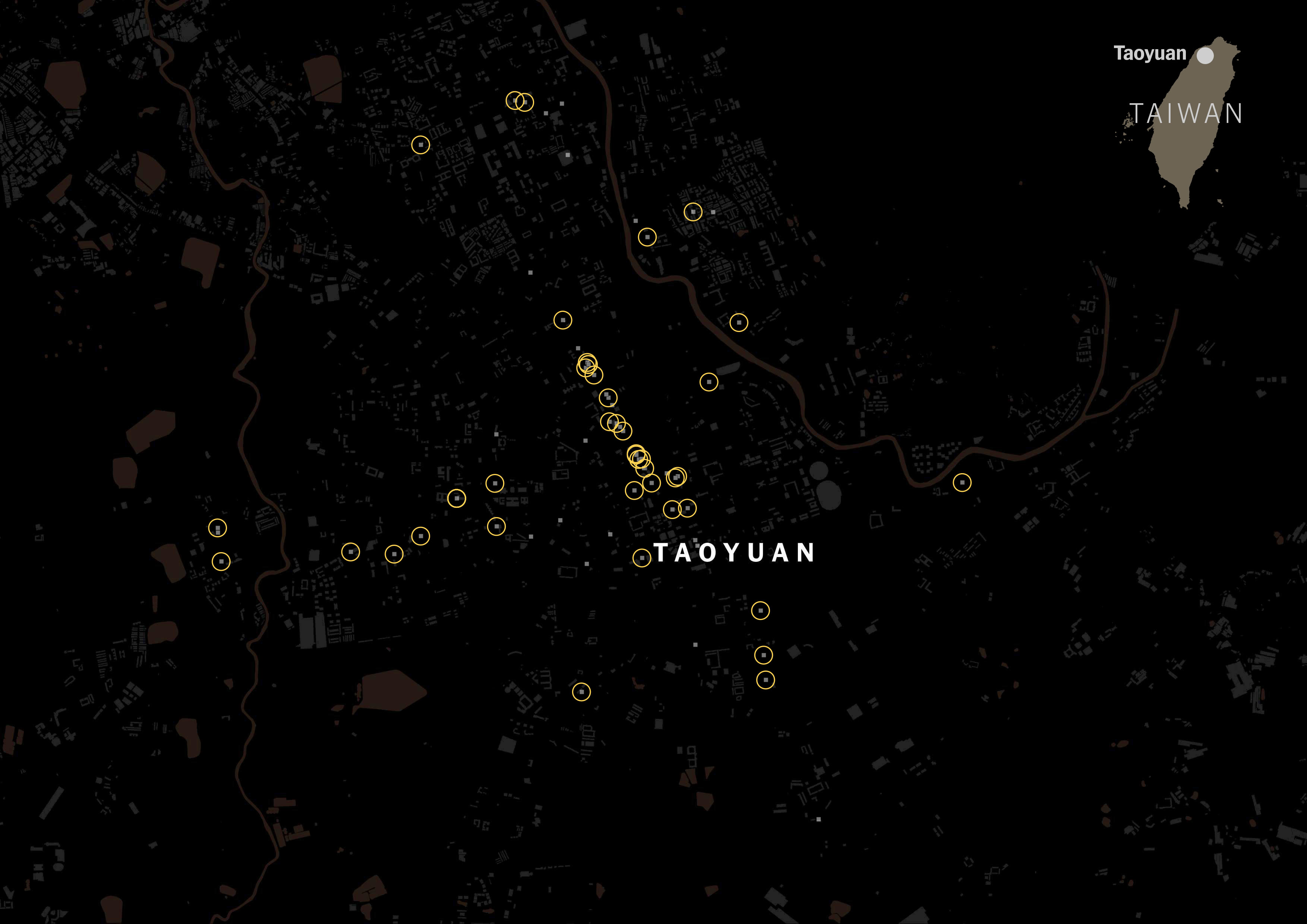
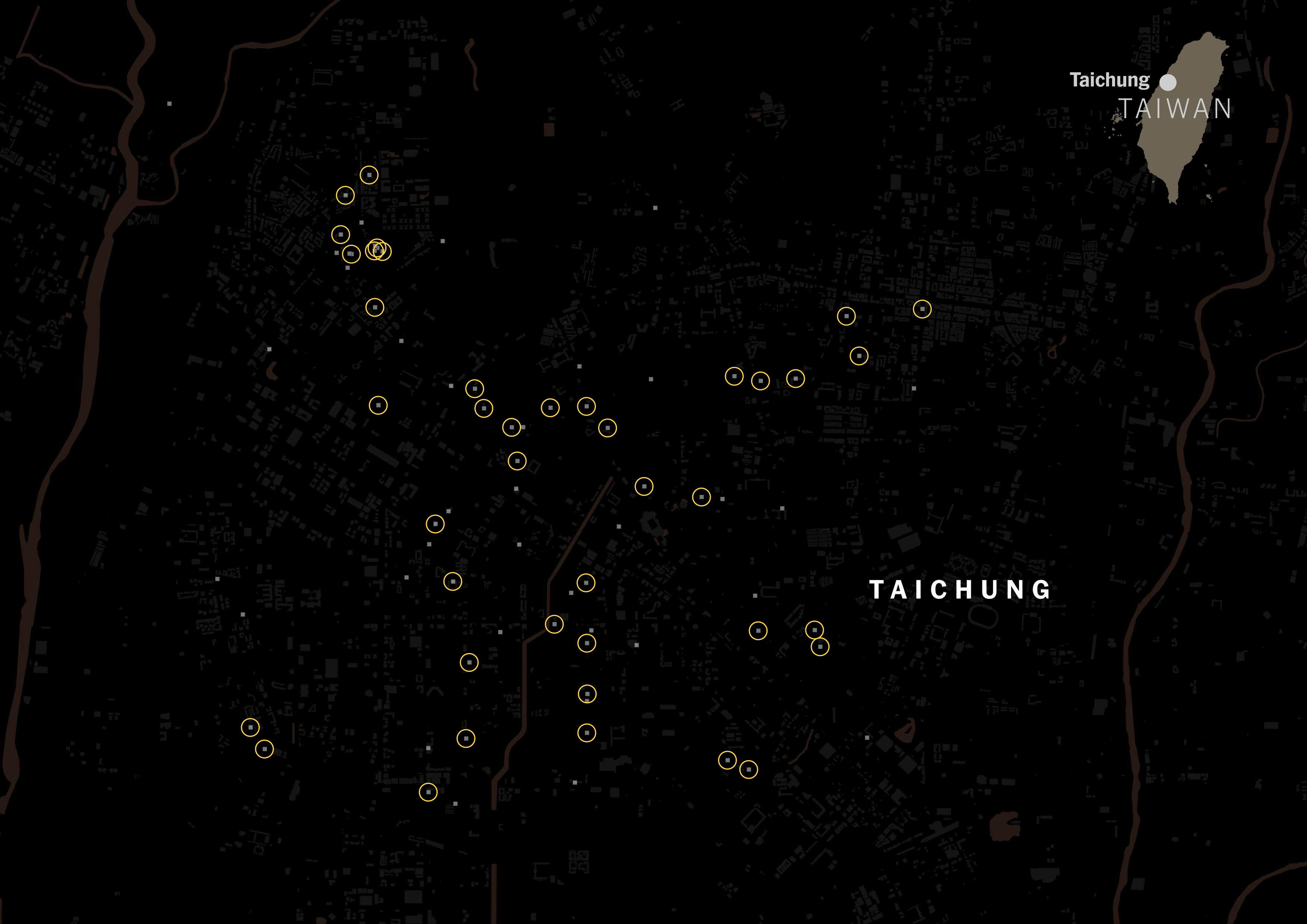
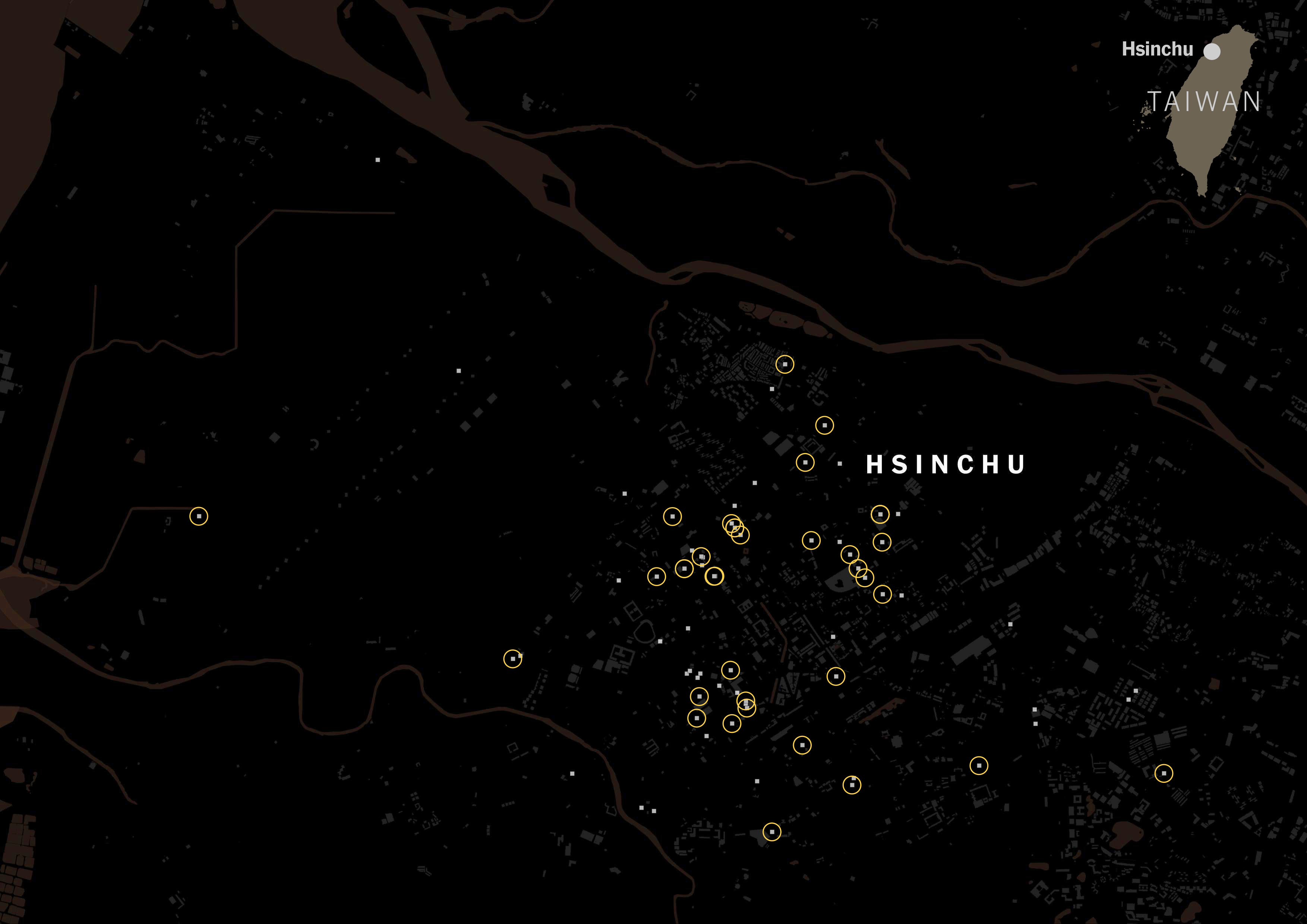
I scrapped that data just to see how popular the Taiwanese tagging versus Chinese tagging. The gray squares on the map below are restaurants listed on Foodpanda and Uber Eats in Taipei:
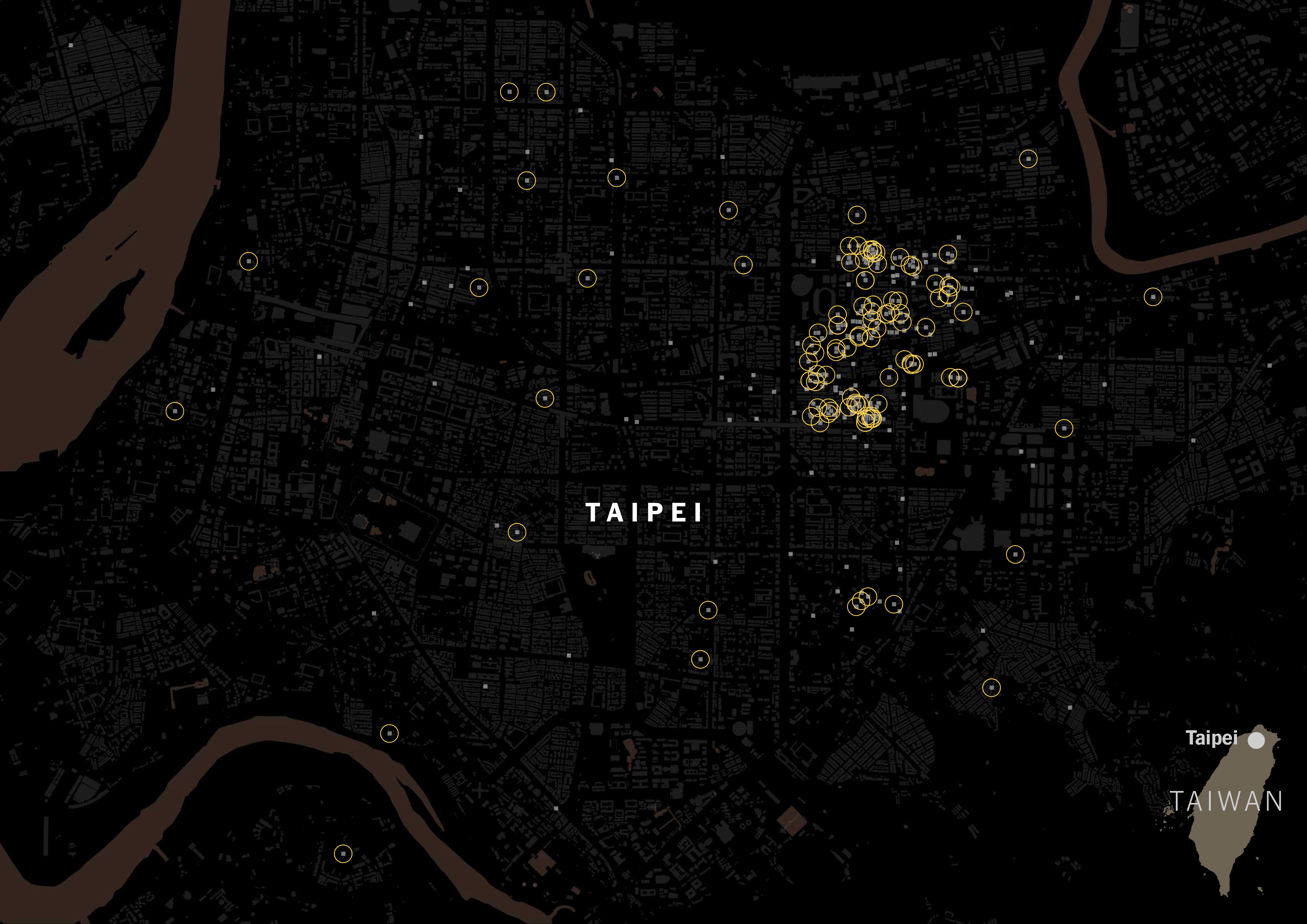
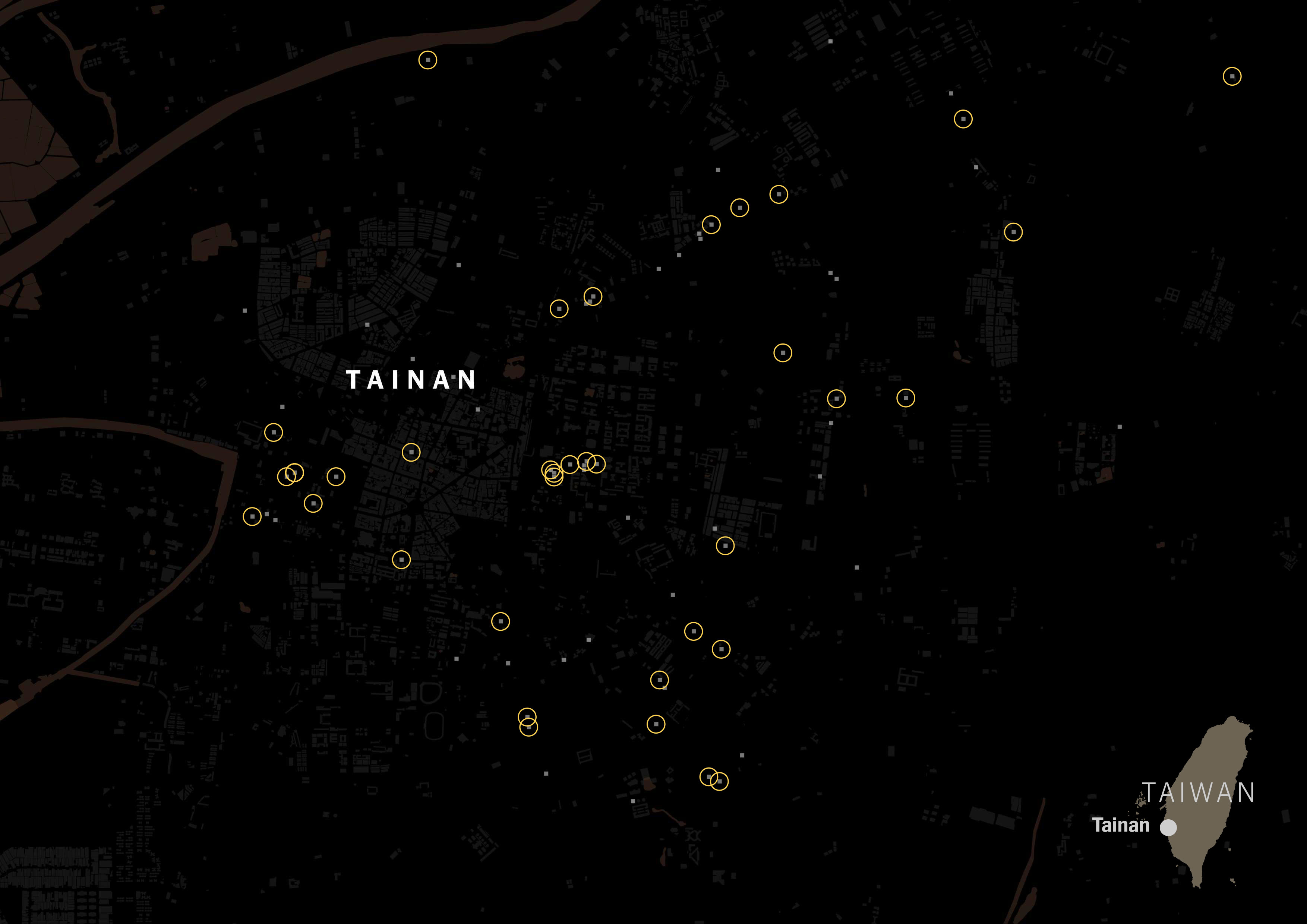
It was really interesting to see how numerous the places with Taiwanese tag were. Look at the same map, but with yellow circles for Taiwanese restaurants.
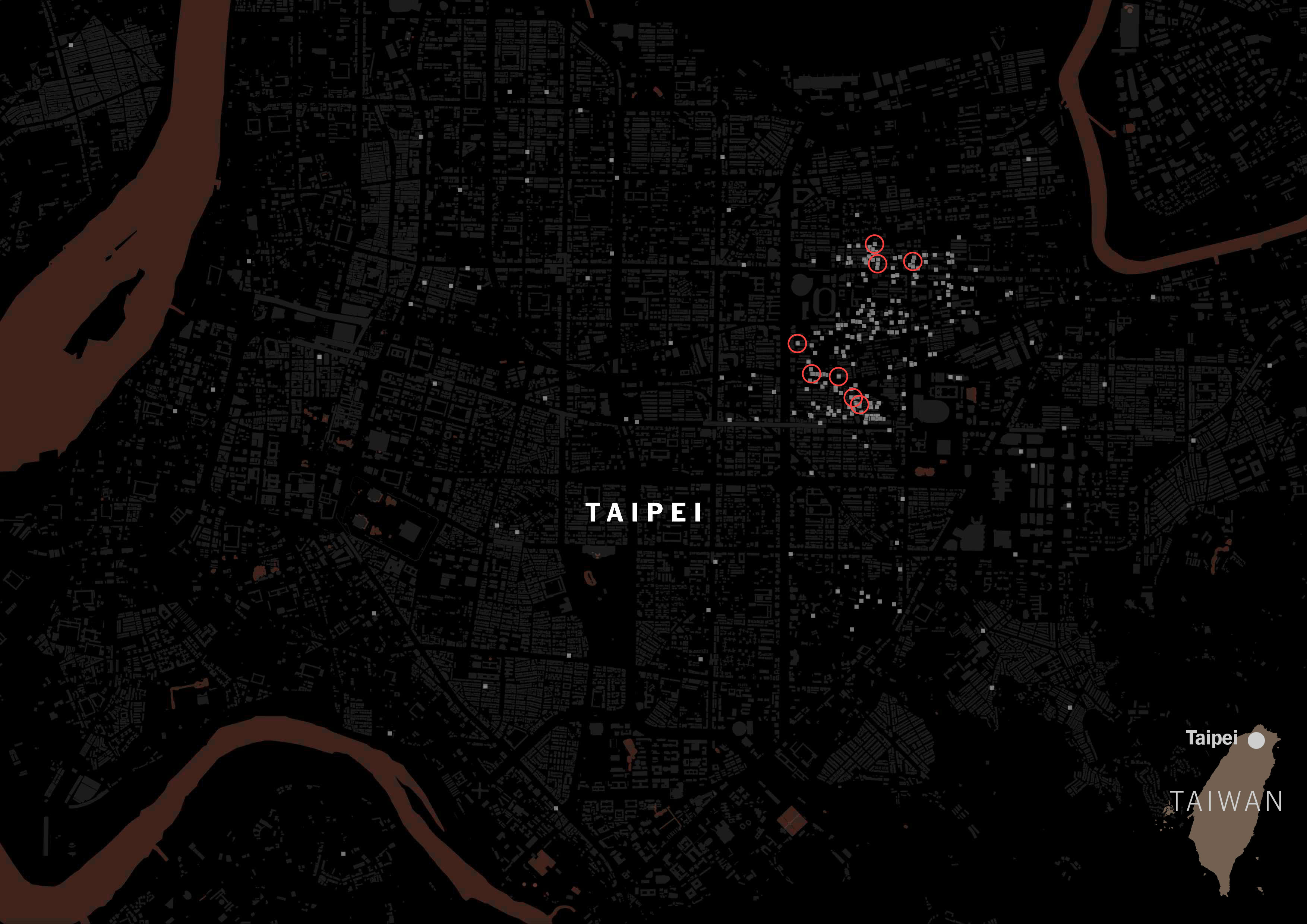
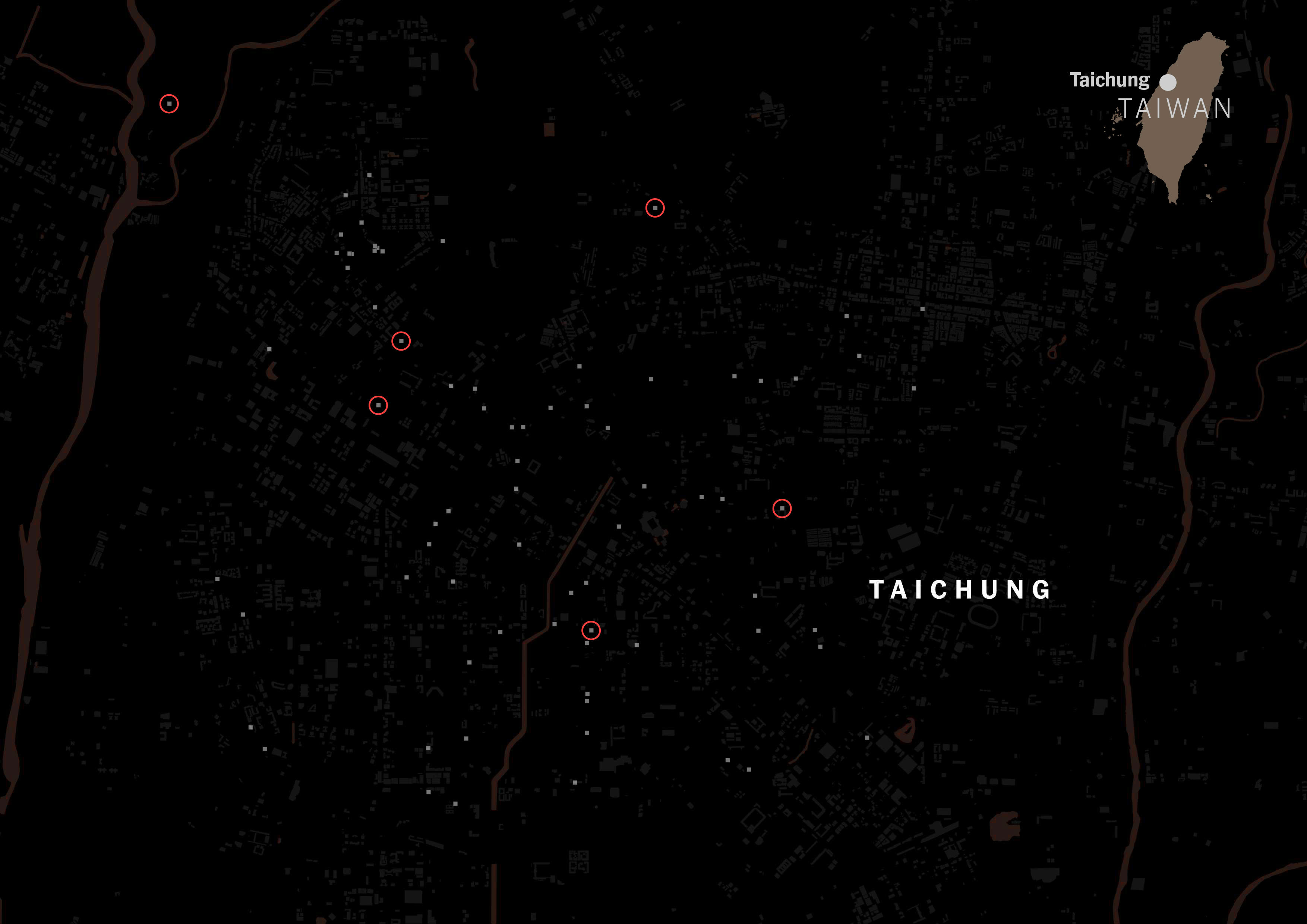
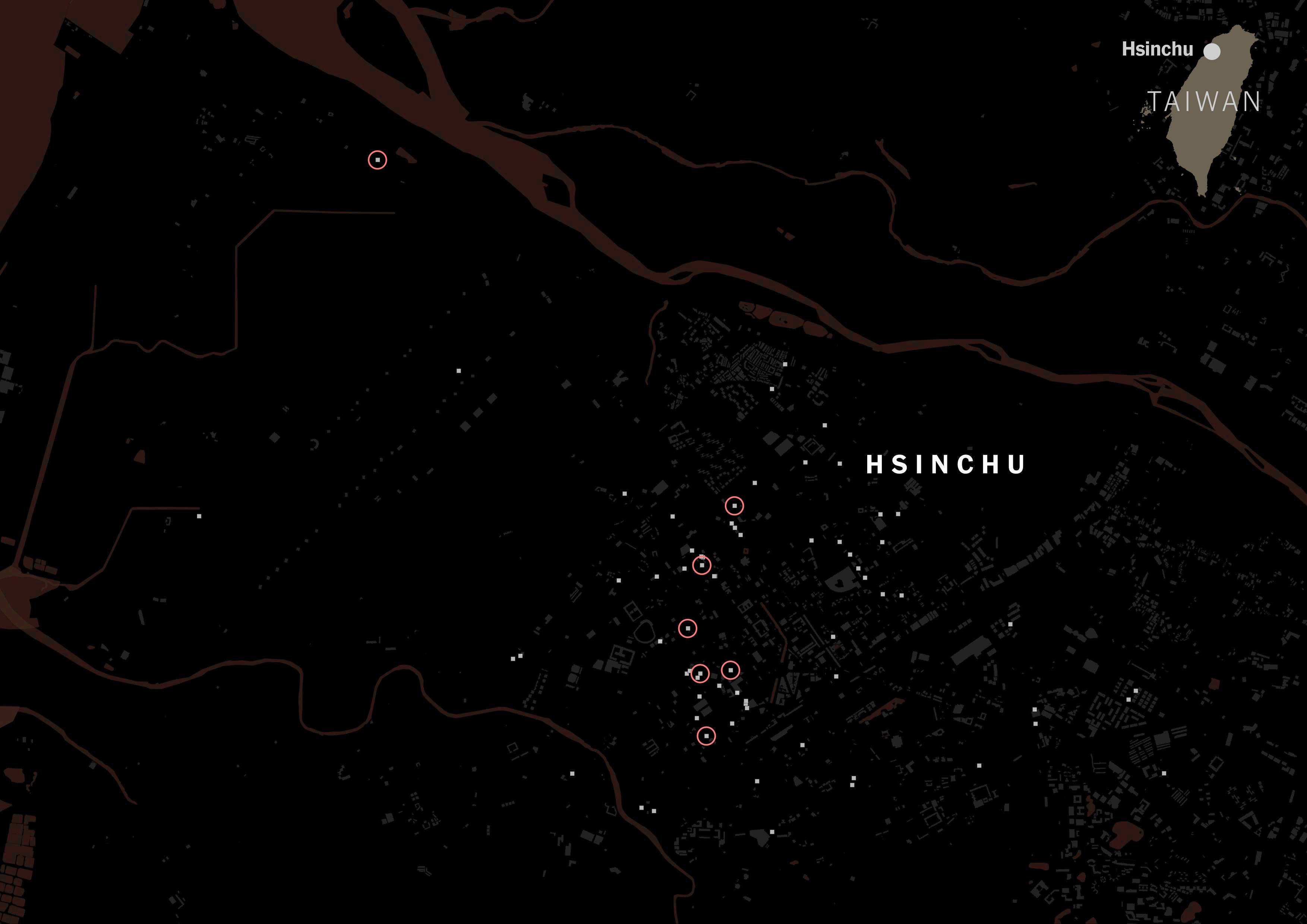
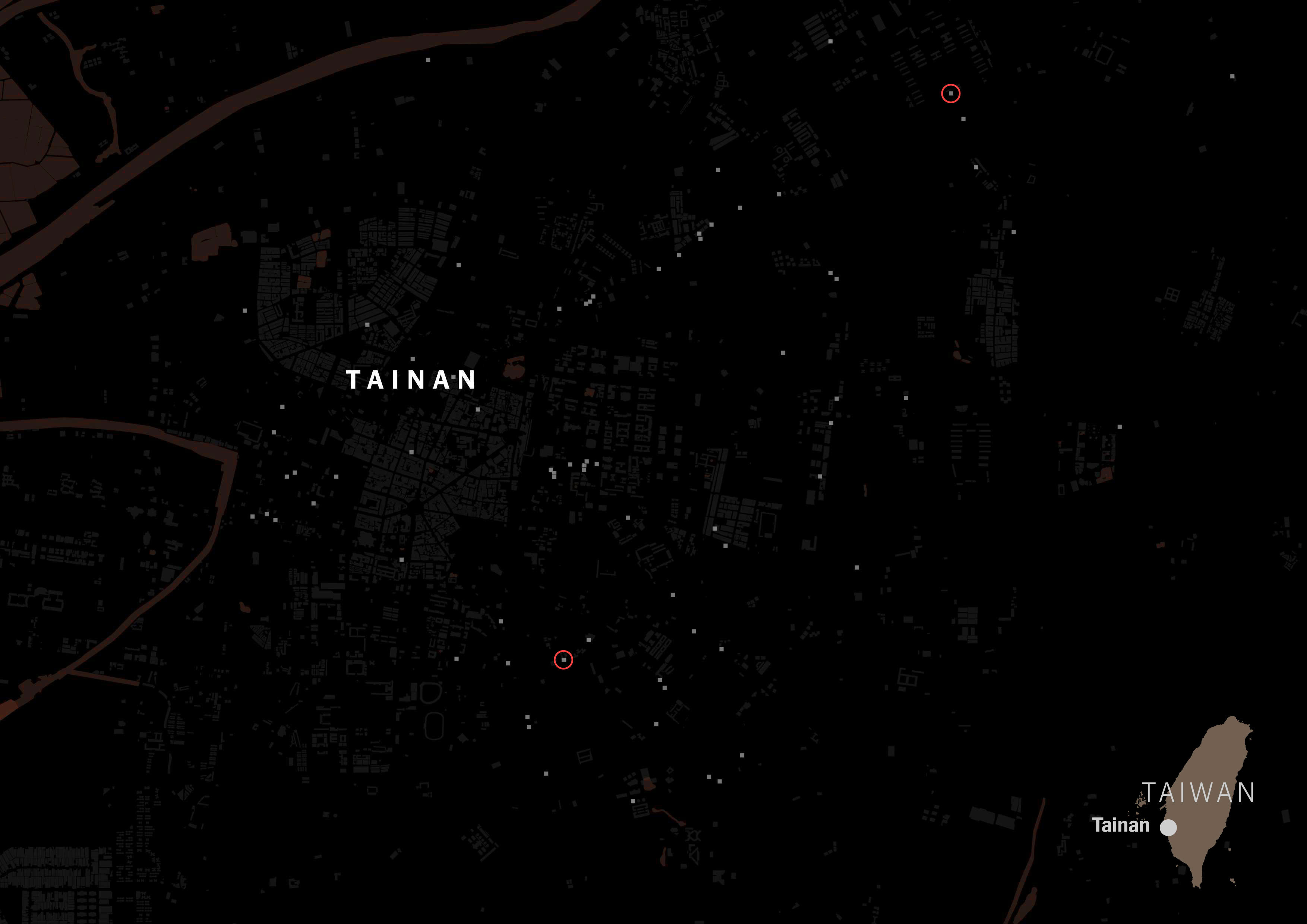
A massive difference with those showing Chinese tags on its categorization. Same map but red circles for Chinese tags.
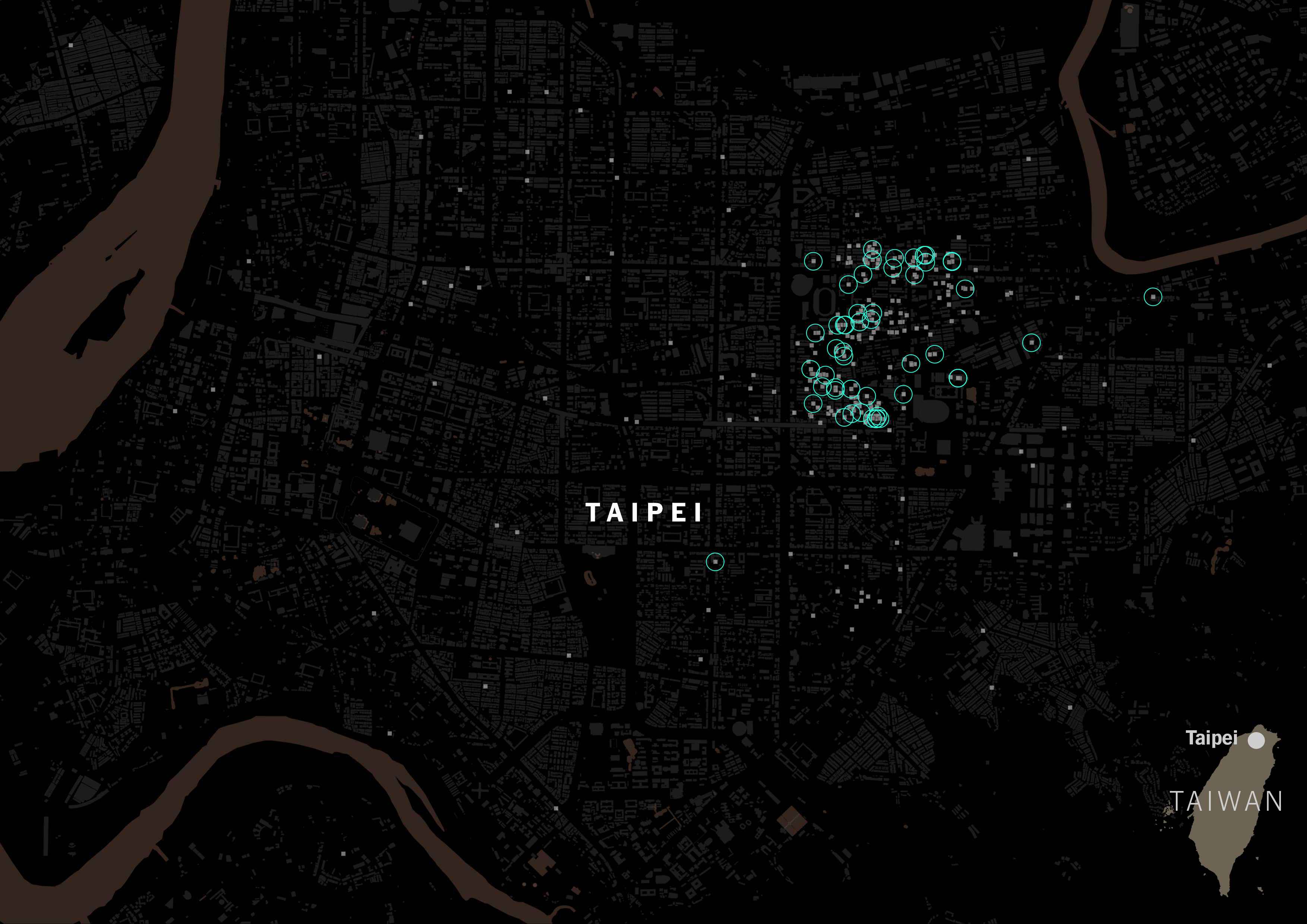
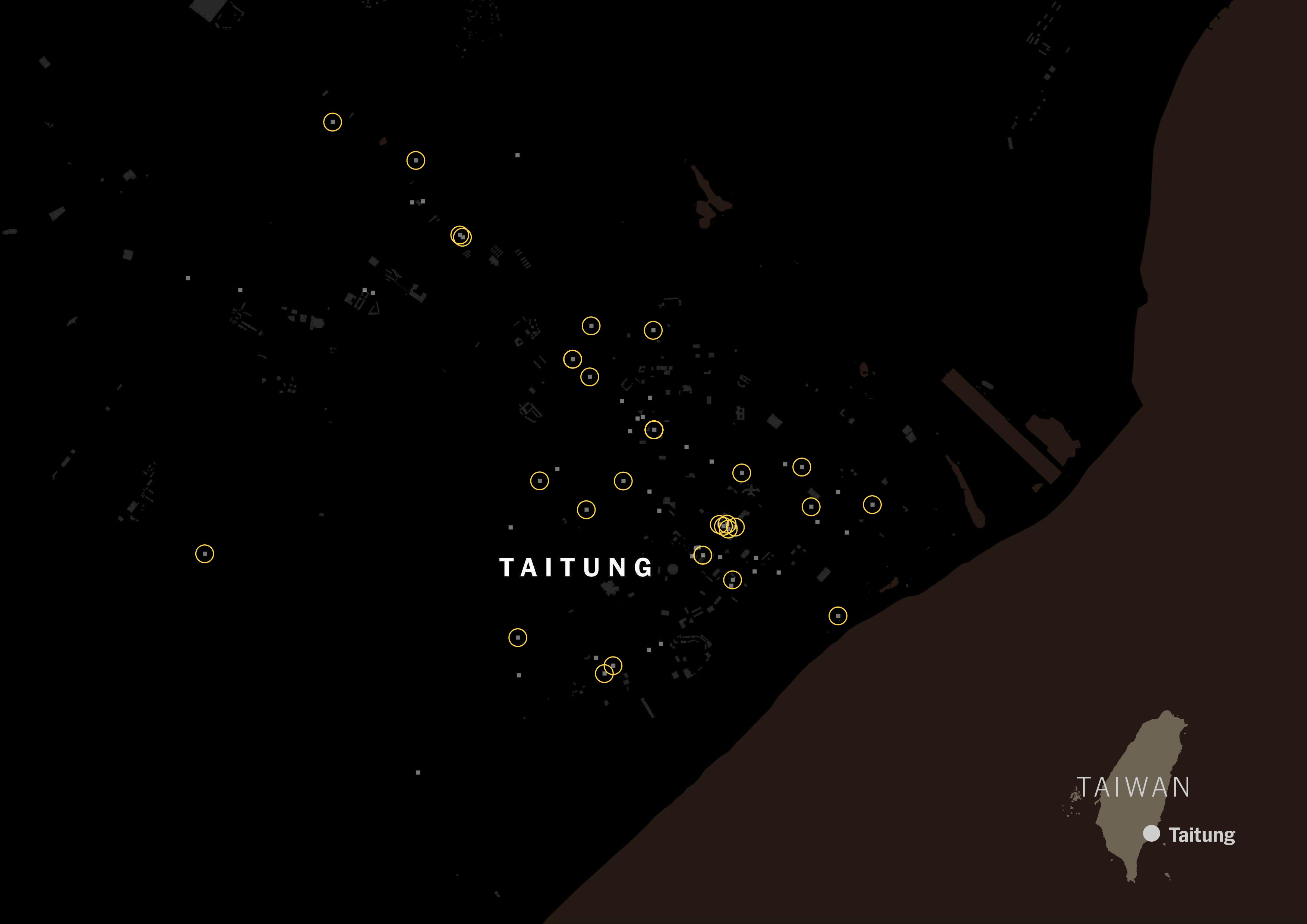
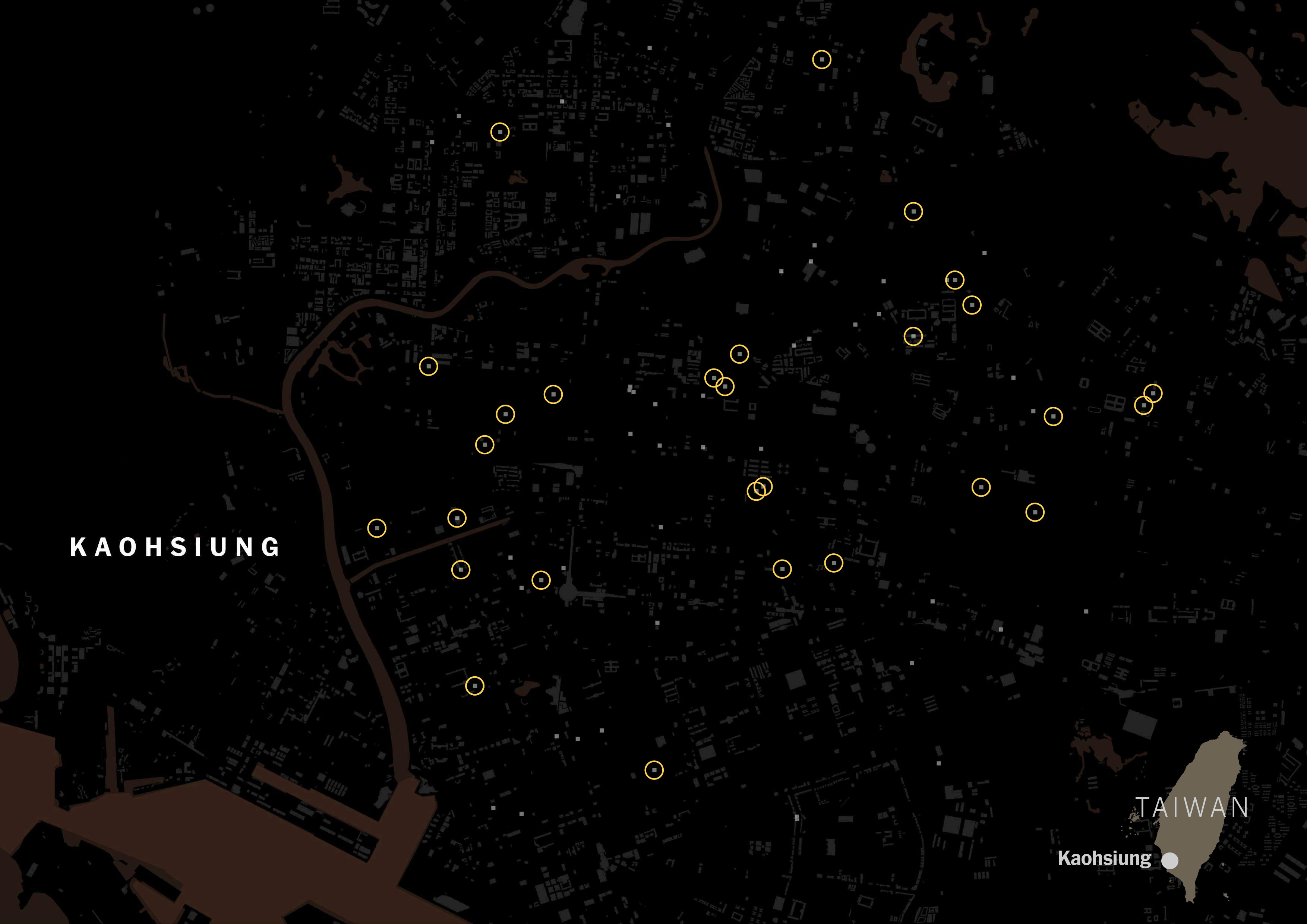
In fact, American tagging for restaurants is way more popular than the Chinese label in Taiwan. Green circles show restaurants with American tags:
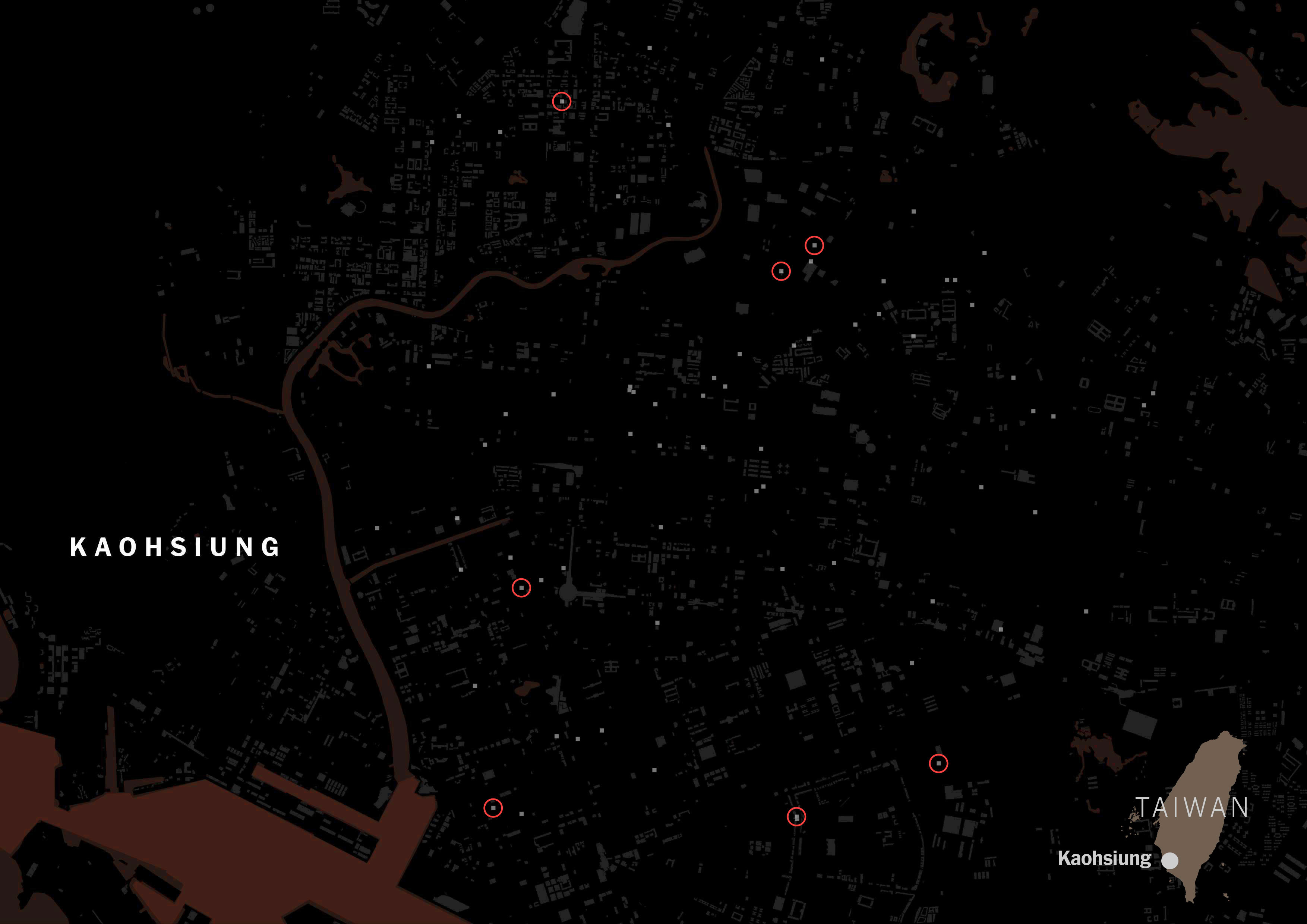
I ran the same script for all of the listed cities in Taiwan for those food delivery services, and the story was similar no matter where you looked along the island. FoodPanda displayed about 4,000 restaurants across Taiwan, 36% of those were tagged as Taiwanese and less than 3% Chinese. Uber Eats followed the same trend, I pulled data for +600 restaurants and 6 of every 10 were Taiwanese, while only 1 or none was listed as Chinese.
I understand some restaurants use more than one tag, but looking at how many of them prefer to be labeled Taiwanese rather than Chinese says something about customer preferences.
They ideas never flourished, I was completely dedicated to Ukraine stories and the data just got older and older. Basically it lost momentum to gain a spot on the news, this happens very often actually, it seems that time is never enough to do all the stories you want to do.
Anyway it was a fun exercise pulling this data and see the trends.
About the data
I used a python script to pull data from Uber Eats and Foodpanda, I’m sure there’s a smarter way of collecting this data… I’m not a developer. But if you want to try your self like I did, you will need to collect all the urls from these companies, often offered by city, then add them into something like this:
from email.headerregistry import Address
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import pandas as pd
import csv
restaurantList = []
driver = webdriver.Chrome('/usr/local/bin/chromedriver')
driver.get("https://www.ubereats.com/tw-en/city/hsinchu-hsq")
name = [ e.text for e in driver.find_elements(By.XPATH, "//*[@id='main-content']/div[6]/div/div/div/a/h3")]
category = [ e.text for e in driver.find_elements(By.XPATH, "//*[@id='main-content']/div[6]/div/div/div/div/div/div[2]/div[2]")]
location = [ e.text for e in driver.find_elements(By.XPATH, "//*[@id='main-content']/div[6]/div/div/div/div/div/div[2]/div[4]")]
dtable = {'Name_ZH': name,'Category': category, 'Address': location}
df = pd.DataFrame(dtable)
df.to_csv('../data/uberEats-hsinchu.csv')
driver.quit()
Note that you may need to install a few dependencies to run this code, but eventually it will spit a lovely .csv file with a column for the restaurant name, a col for address and one more for category listed in Uber Eats. Food Panda uses a different structure, but the code is pretty much the same except by the urls and the targeting of fields.
If you are working on something similar, I’ll love to see the outcome, reach me out on Twitter.
About infofails post series: I believe that failure is more important than success. One doesn’t try to fail as a goal, but by embracing failure I have learned a lot in my quest to do something different. My infofails are a compendium of graphics that are never formally published by any media. These are perhaps many versions of a single graphic or some floating ideas that never landed.
In short, infofails are the result of my creative process and extensive failures at work.
Are you liking infofails?, have a look to previous ones:
This is what happens when you are out of sync. I just published one more entry of #infofails. If you’re not familiar with it, infofails is a summary of my creative process and extensive failures at work. Check it out here:https://t.co/jjWL8ydUPgpic.twitter.com/6VLu2XJDfo
Earlier this year I spent some time learning about the world of phenology. After reading some scientific papers and doing some interviews with researchers, I just found myself getting more and more curious about it.
If you google Phenology it will return something like “Phenology is the study of periodic events in biological life cycles and how these are influenced by seasonal and inter-annual variations in climate, as well as habitat factors.”
Since we live in a single network, studying the effects of climate on species brings us closer to what will inevitably also affect us, but it’s also a way to connects us a little more with all those other living beings with whom we share this space.
“The love for all living creatures is the most noble attribute of man.”
Charles Darwin
Darwin was right, after talking to a lot of people and understanding their passion for plants and animals, it is easy to understand the concern about the changes that some species are facing.
But moving on, if you have visited this blog before you may know where this is heading to… yup, this is another #infofails story. Here’s how all went wrong:
An unfinished illo for a blooming/ecological mismatch project I tried to run.
The embarrassment
The most embarrassing part of my failures is not facing your editor with a dumb idea, the hard part is getting excited about the information from sources and interviews and then watching time go by without you being able to develop the story you had in mind, especially if the people who spoke to you were super collaborative.
My first source in this endeavor (with whom I’m still embarrassed) was an Ecologist with the USGS. She shared with me some info from studies in the Gulf of Maine where she studies seasonal disturbances in marine life. In fact, it was she who explained to me what Phenology is. –Explained by a scientist who works on it.
My embarrassment also is with Richard B. Primack. He’s a Biology Professor at Boston University, I had a great conversation with him, he shared tons of great data.
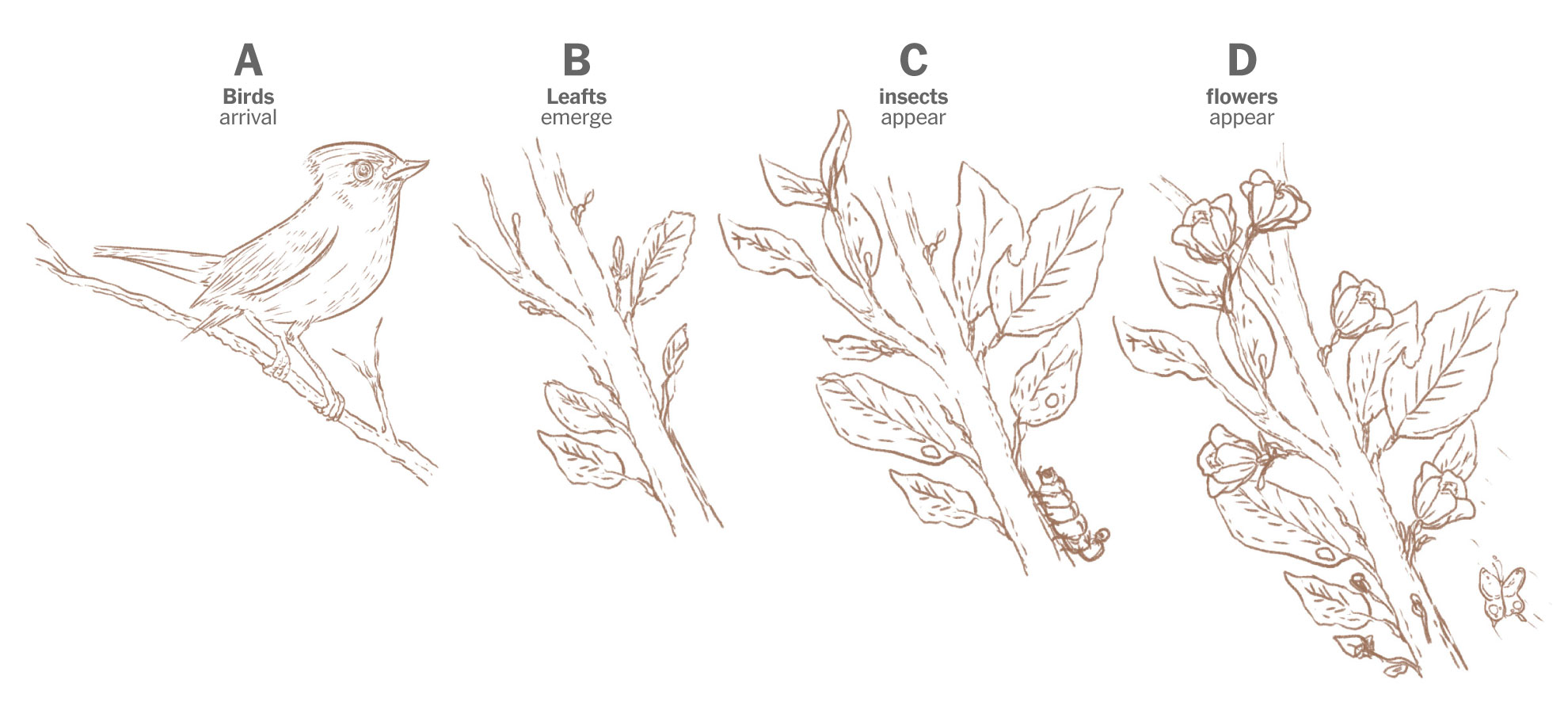
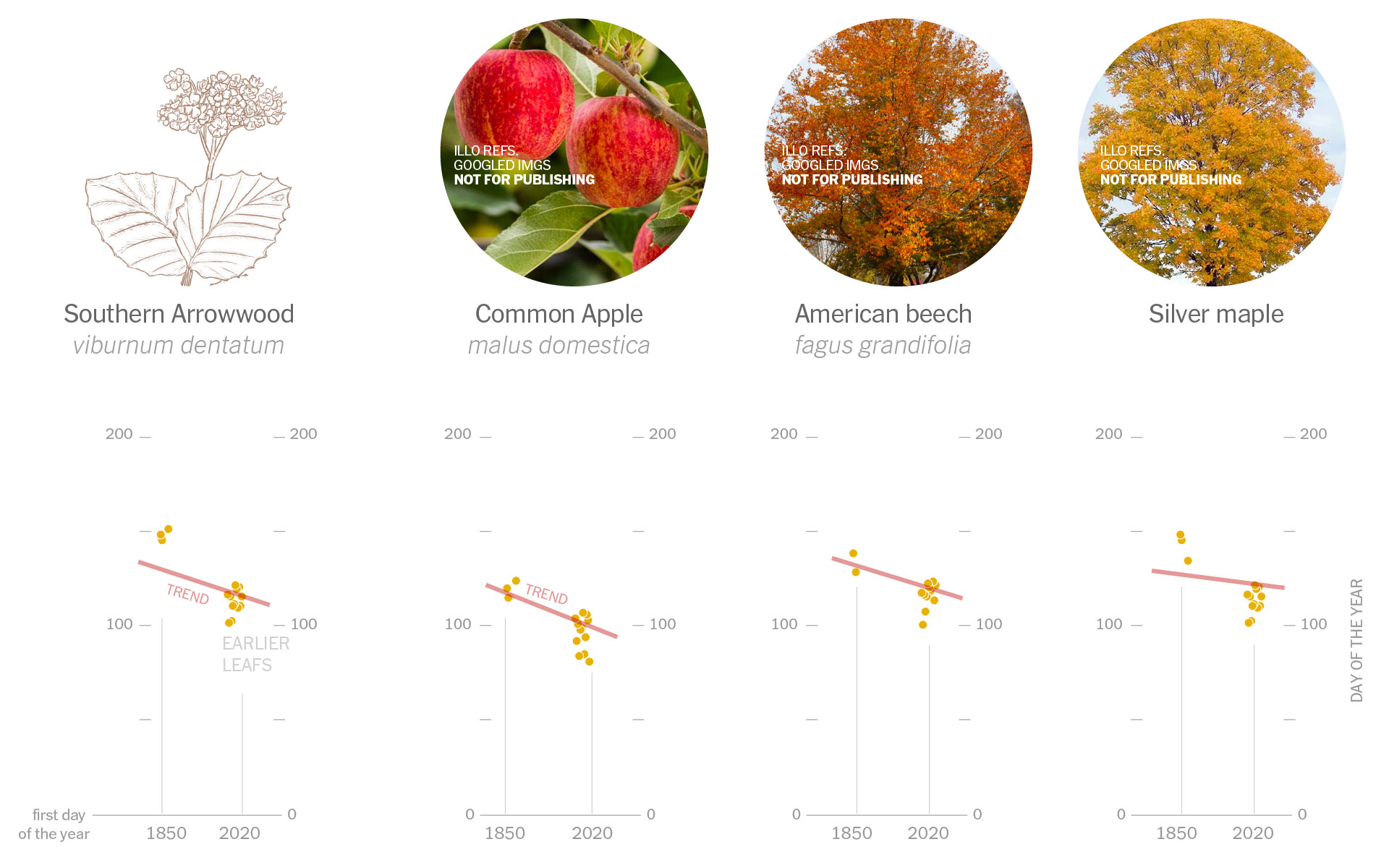
You see, Prof. Primack has been studying and documenting the ecological mismatch for years, in 2016 he published a study where he explained how some birds arrived late to forage because spring is starting earlier. He show this example comparing the spring in 1850 describing the natural flow: first birds arrive, then leafs come, then insects appear, and finally flowers pop. Here’s a quick draft I did based on his publication:
Sketches of the spring flow in 1850. Based on Prof. Primack’s paper published in American Scientist Magazine, 2016.
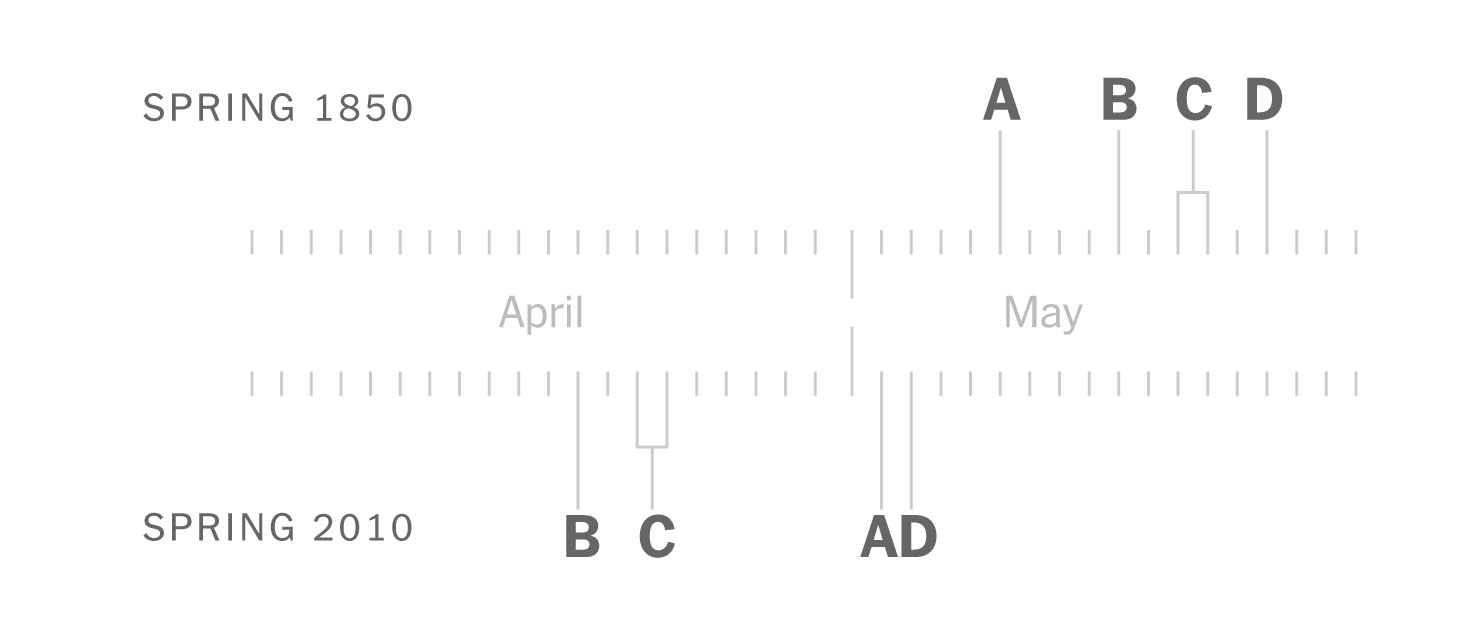
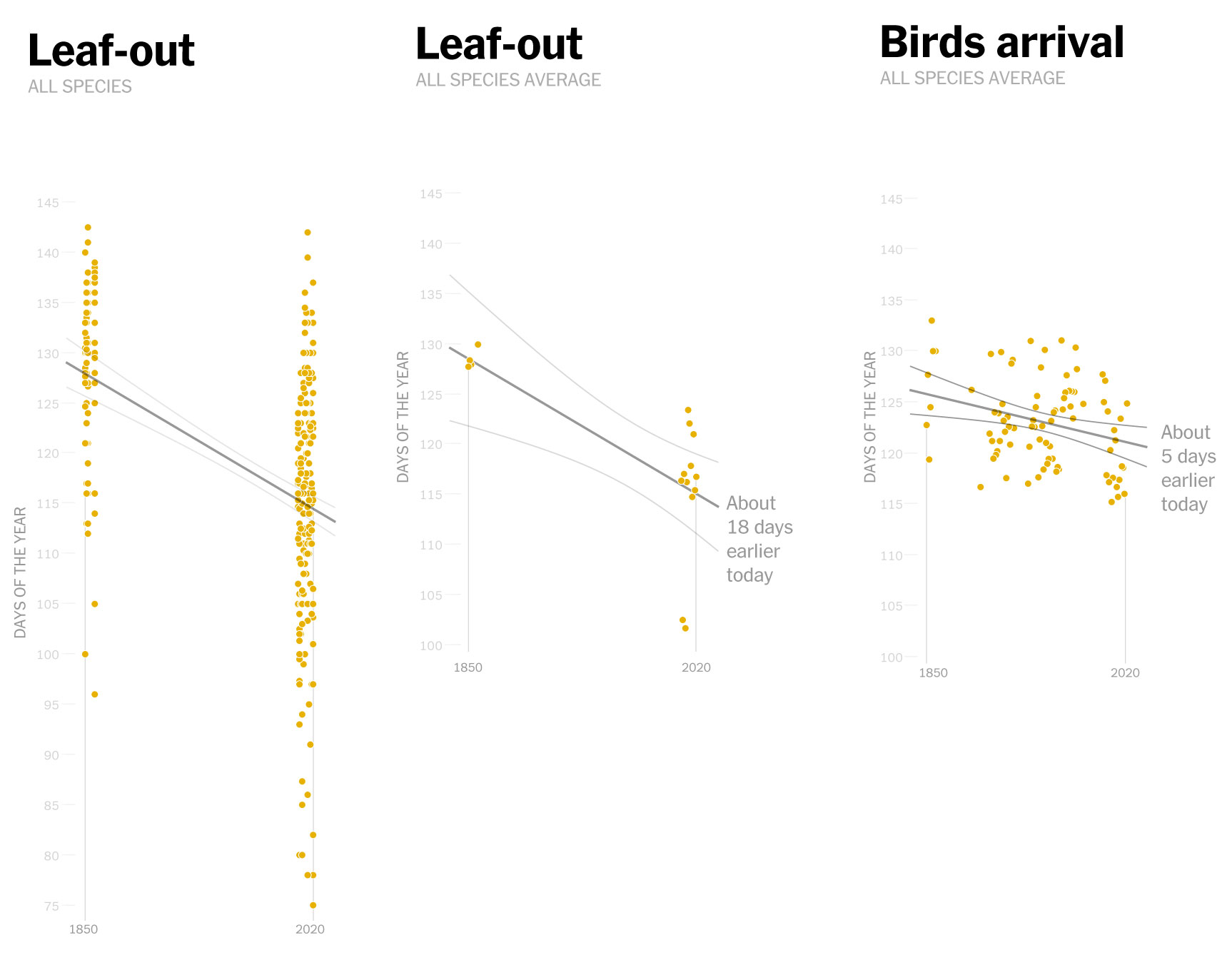
Makes sense doesn’t it? the observations show that these birds have continued to arrive on similar dates, but now spring is coming earlier. In 2010, for example, the leaves arrived earlier, so the insects also appeared earlier and spoiled the entire cycle for other species.
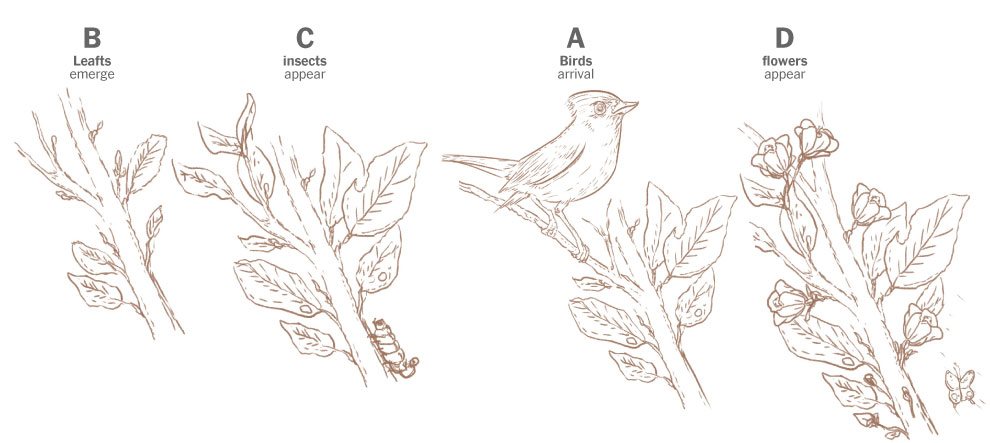
Staying with that same example from 2010, birds were observed arriving around the same date to find flowers when the insects should be just showing up. In other words, these days, for some species the natural flow looks something like this:
Sketches of the spring flow in 2010. Based on Prof. Primack’s paper published in American Scientist Magazine, 2016.
Prof. Primack along with many others researchers used Henry Thoreau’s observations to reconstruct the past of seasonal changes, that alone was a big story for me. So I went on and on, making more questions and asking for more data. And kindly they send me over tons of papers and tabular data.
Some of that data Prof. Primack shared with me included detailed records of plants and animals where he spotted those changes in spring and the struggling birds.
A data sketch I did with part of the data collected by Prof. Primack and a team of researchers merged with Thoreau’s records.
When I have a dataset that looks this interesting, I’m inevitably driven by ideas of how to show this in a story, it’s like a need of sketching data. At that point I need to somehow present this to my editors to push it forward and turn it into a story. Sometimes I spend time developing my ideas into sketches just to explain to editors what I’ve found interesting, but it’s not always as obvious to them as it is to me, so it’s necessary to write some paragraphs and accompany them with those images.
Some of the tree species that sprout leaves earlier. The steeper the slope of the red line, the earlier the leaves sprouted on average.
Just the right timing
That same process that I follow sometimes takes too long to put together a draft for my editors. When I came up with the proposal for this story, it was almost spring and it was hard to move a story past that window. That was just one of the things that spoiled the initiative I think.
It’s important to note that for those types of stories, I’m not developing the drafts over my daily work, but rather in free moments, which lengthens the process even more. But anyway, the lesson of this part was to keep an eye on your post window and not let your inner child distract you with what you find and diverge, maybe you’ll get the idea to the editors in time, it would be more easy for this to happen, who knows…
Adding more, more, more…
Certainly I was fascinated with the data and all the potential for a story, I was finding more and more data related to the same issue of animals struggling with the climate changes, the only problem was the this data was a little old already. Like this fascinating 2018 paper by Prof. Marketa Zimova + describing molting conditions in furry animals and how they struggle to survive when there is little snow and you are still covered in white fur. You may noticed the illustration at the top with a white hare on brown background which is kind of what they look to predators when there’s no snow around. Really sad the reality that these animals are going through, you know how it ends if you’re a white prey animal on a brown background.
A diagram based on the research data by Prof. Marketa from the University of Montana.
My second problem turned out to be that I was following the white rabbit into the world of tangencies. There is so much information on this that I started to integrate other studies and data, maps and things that led me to create a monster draft. A lot to digest from a news perspective maybe.
Earth temperature anomaly in April 2007. Based on NASA NEO. This event caused heavy damage to fruit tree crops during the spring of 2007.
A lesson from this would be to narrow the focus, crunching the idea down to its essentials can help early in the process. My mistake here was probably in choosing and editing the story I intended to show my editors. I added a thousandthings on it, including interesting but a bit old data, maybe not the best selection for a news story.
While not everything should be breaking news, at least the focus of the story should be less scattered and consequently better defined.
Don’t follow the white rabbit. They tend to show you things that lead to a spiral of tangencies. –A silly and perhaps inappropriate joke, sorry. I hope you get the idea anyway.
We are experiencing climate change in many ways. In fact it’s easy to find news and research papers on early blooming and animal habitats threatened by seasons arriving earlier or later than they used to be and so many other changes that every species on this planet (including us) must endure.
If you’re in to news, I encourage you to talk more about this topic, worst case scenario don’t publish your story, but at least you’ll meet amazing people along the way and learn a little more about the fascinating world between us.
About #infofails post series: I truly believe that failure is more important than success. One doesn’t try to fail as a goal, but by embracing failure I have learned a lot in my quest to do something different, or maybe it is because I have had few successes… it depends on how you look at it. Anyway, these posts are a compendium of graphics that are never formally published by any media. Those are maybe tons of versions of a single graphic or some floating concepts and ideas, all part of my creative process.
In short, #infofails are a summary of my creative process and extensive failures at work.
Are you liking #infofails?, have a look to previous ones:
I’m not as consistent as I wish but I hope you keep enjoying #infofails this time dedicated to #maps ‘Random Failed Map Details’ https://t.co/TxDcUTuYat
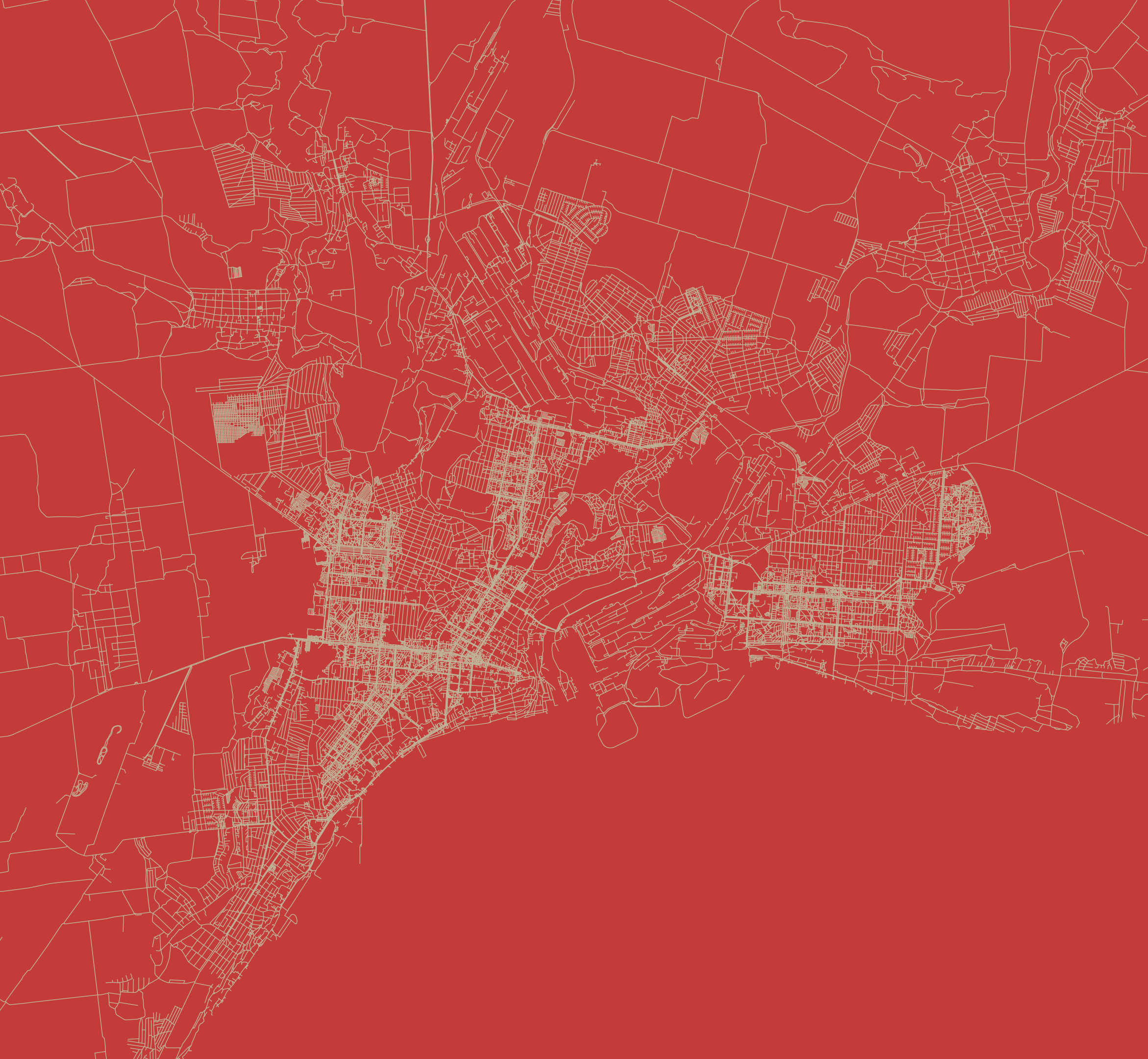
Recently I have been working on maps, maps and more maps. I really like the world of cartography, although I’m not a cartographer a lot of my work includes trying to make maps for news. –My apologies to my carto-friends who actually do this properly, I’m just an enthusiastic fan with perilous initiative. 🤣
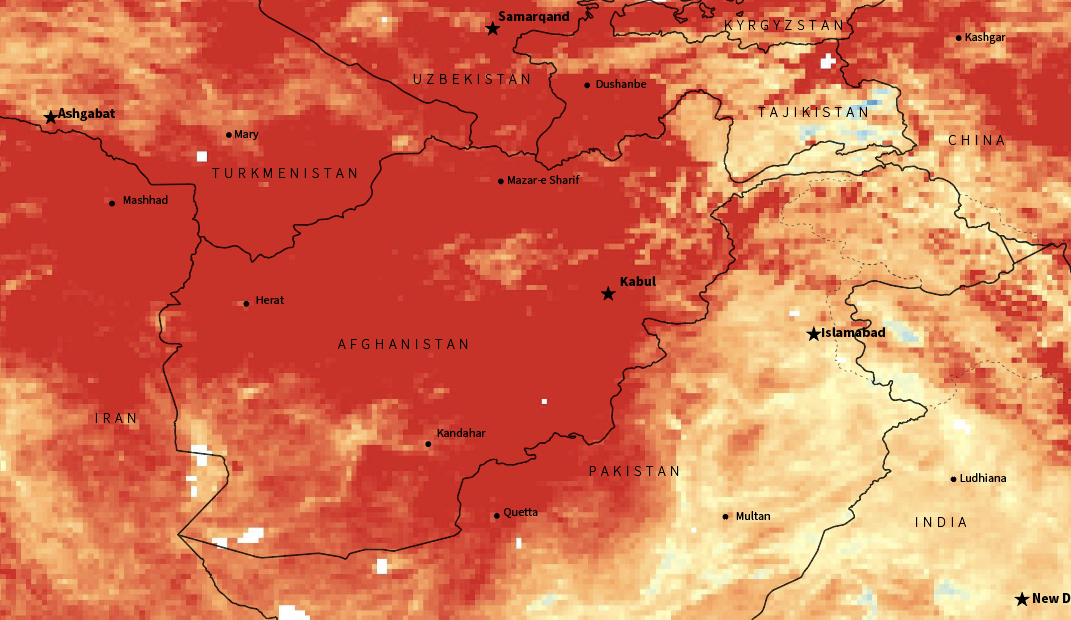
Since I moved to the NYT, I have been in a process of rebooting, adjusting myself to the new environment learning new stuff and understanding how things work in this side of the world. But as usual, while I’m executing random ideas I have left behind a bunch of un published visuals like the screengrab at the top of this entry which is a DEM of an area of eastern Ukraine.
For nerdy purposes, the image at the top and the following are SRTM elevation and Open Street Maps data processed with QGIS with a little color retouch in Photoshop.
A failed map of eastern Ukraine.
Of course these detailed images doesn’t work well for the purposes of the news story I was working on. If you have seen our Ukraine maps coverage, you’ll notice that while our maps have evolved, they also keep consistency somehow. To be honest, I made those alternate versions because I couldn’t stop thinking about how this would look in another style. You can see what I mean below, these are the same area in eastern Ukraine rendered for different purposes:
Alternative terrain section of eastern Ukraine including part of the Sea of Azov at the bottom
Screenshot of the piece published by the New York Times
Alternative terrain section of eastern Ukraine including part of the Sea of Azov at the bottom
Here are some closer shots of that map above, the geography of this region of Ukraine is marvelous.
There are so many of these maps, I have literally spent months looking at the progress of the war with maps, many different approaches and a heavy editing process of what takes place until the final version of the story. It is a strenuous process but super interesting at the same time. I feel very grateful to be able to see all this and be part of the search for the truth to inform the readers of the NYT.
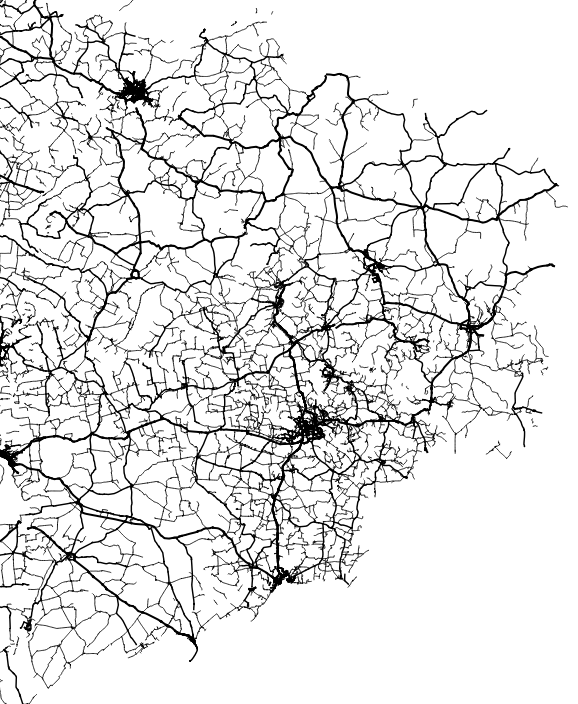
Basic vectors
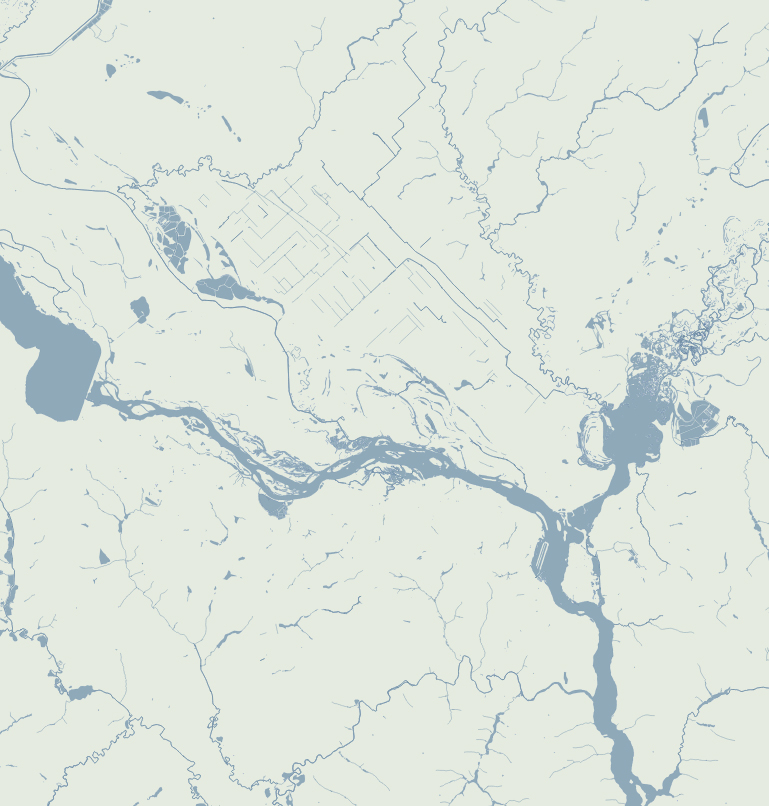
There’s something with the base layers, is amazing how you can see the population density of a place just by plotting roads. Some areas with certain road layers look like leaves or some kind of vein system. [ Click on the images to see a larger single image ]
The same thing happens looking at water features, some times you are able to see canals making geometric patterns in contrast to the organic river beds.
Since Ukraine has vast tracts of land dedicated to agriculture, those patterns are clearer in some regions, however the rivers and lakes are still fascinating as well.
About #infofails post series: I truly believe that failure is more important than success. One doesn’t try to fail as a goal, but by embracing failure I have learned a lot in my quest to do something different, or maybe it is because I have had few successes… it depends on how you look at it. Anyway, these posts are a compendium of graphics that are never formally published. Those are maybe tons of versions of a single graphic or some floating concepts and ideas, all part of my creative process.
In short, #infofails are a summary of my creative process and extensive failures at work.
Are you liking #infofails?, have a look to previous ones:
August 2021 saw a tsunami of stories from Afghanistan in the news. Apart from a bunch of small graphics, I participated with “Chaos in Kabul“ and “Flights over Kabul“ both stories related to the Afghan skies and the complex situation lived there after the US troops withdraw. At Reuters, we did a good long list of potential stories, even I did a few kickoffs of some, but a packed agenda of long term projects for this year left most of them out.
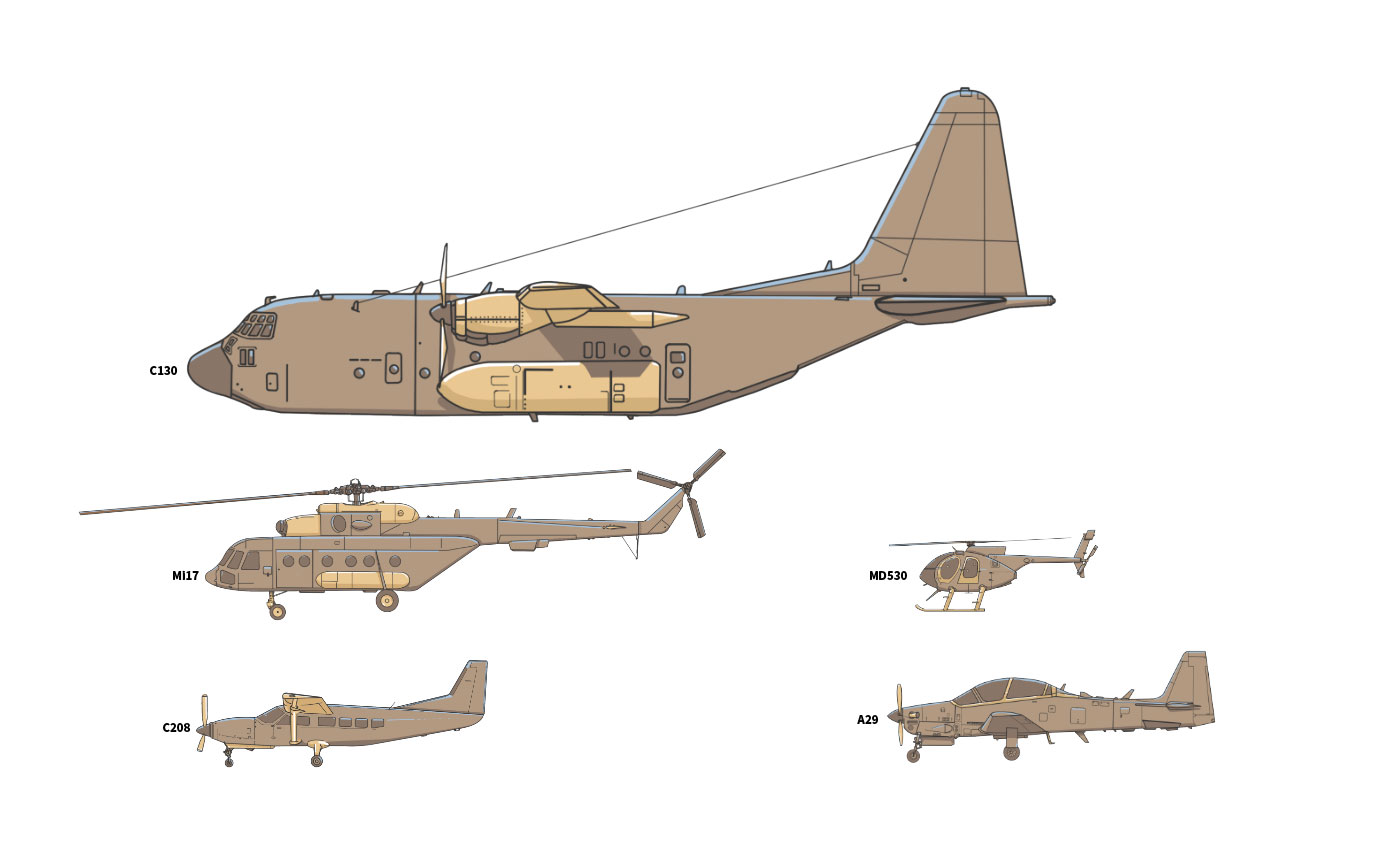
illos published at the story “flights over Kabul” Aug. 2021 | Reuters graphics.
Have you ever felt that you need a few copies of your self to materialise all the stuff in your mind? no? well maybe just me weirdo but I do. I would have loved to have some copies of me working on a few more stories from Afghanistan to get them in time to publish back then.
Those aircraft illos above are from stories that do made it, but you know I love to share pieces from under the rug, so… here you go:
For a day or two my desktop was full of guns blueprints, aircraft dossiers, technical documents of military equipment, tons of field photographs from our news feed, news articles… The home screen of photoshop and illustrator slowly turned red.
I usually start these things in photoshop, drawing outlines, then a base colour layer, a layer shadows and one more of lights on top. All always to scale and 2.5x the size I’ll need in the final version.
The cool stuff related to my job. ❤
The night vision googles were my favourites, weird device actually. I learn some of them are like a video game with this cool display of augmented reality. The visuals looks really nice, check this story from The Washington Post [ here ] or just google “US army augmented reality night vision goggles” you will see.
I love to learn new things, that’s one of the best things of my job actually. You never know what’s waiting for you tomorrow, what new curiosities are waiting there for you. And even if they don’t get published for sure you will learn something new.
The grey area of working in news
Beyond the research for the illustrations and the drawing itself, I made some maps and videos on a demo page with the proposal. Maybe all of this was pointing too high in the little time we had at the time since all the rest of the work has to be considered to complete the story.
Sometimes news are a bit cruel, you must do everything quickly before it’s no longer news. The tricky part of it is that most of us in this industry think quickly of the same things. It’s like a race against the clock, so, unless you can distinguish your story from others that have been already published, things are doomed, and may end here on my blog… which is fine, but of course it’s a sad thing to bring potential stories to the graveyard.
The summary of this failed idea contains a fair amount of learning, a lot of cool nerd stuff is on my head now. Although unfortunately none of this was published, it was not a complete waste of time either as I did not work on this exclusively. There are many other interesting things in the pipeline, some almost done, so enthusiasm always remains high.
About #infofails post series: Graphics that are never formally published. Those are maybe tons of versions of a single graphic or some floating concepts and ideas, all part of my creative process. All wrapped up in #infofails, a compilation of my creative process and failures at work.
Did you like #infofails? Have a look to other #infofails
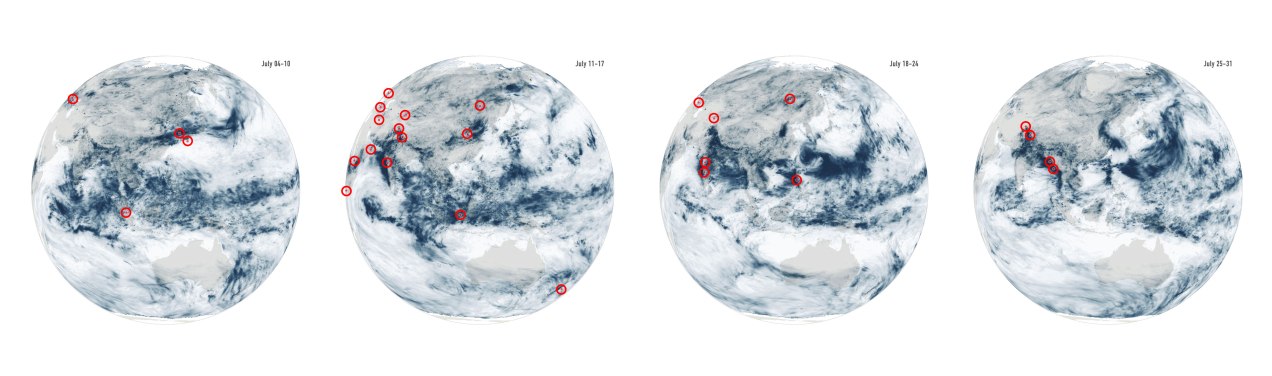
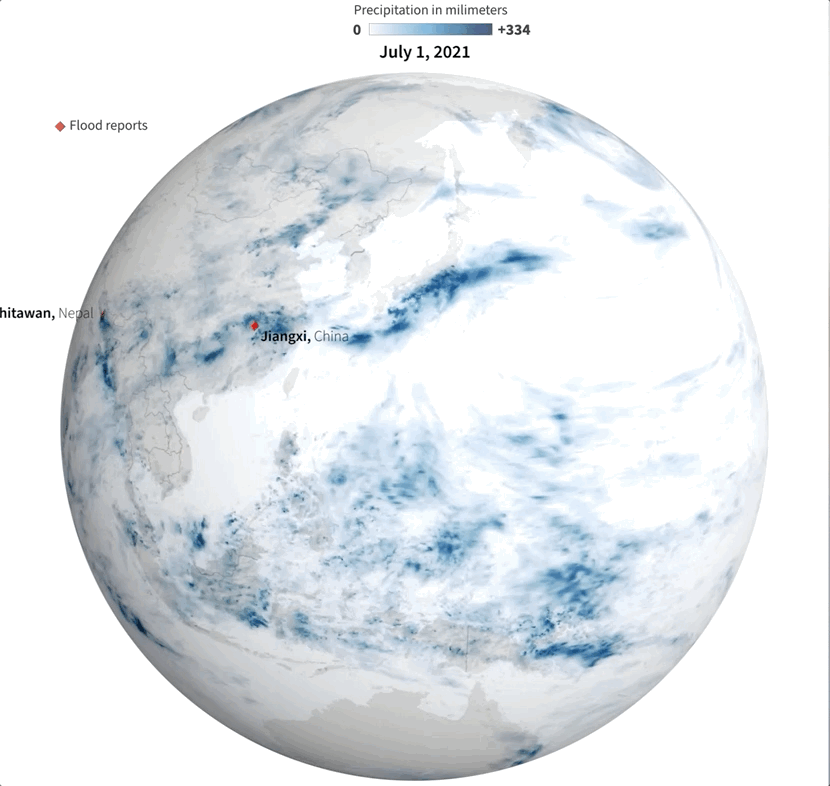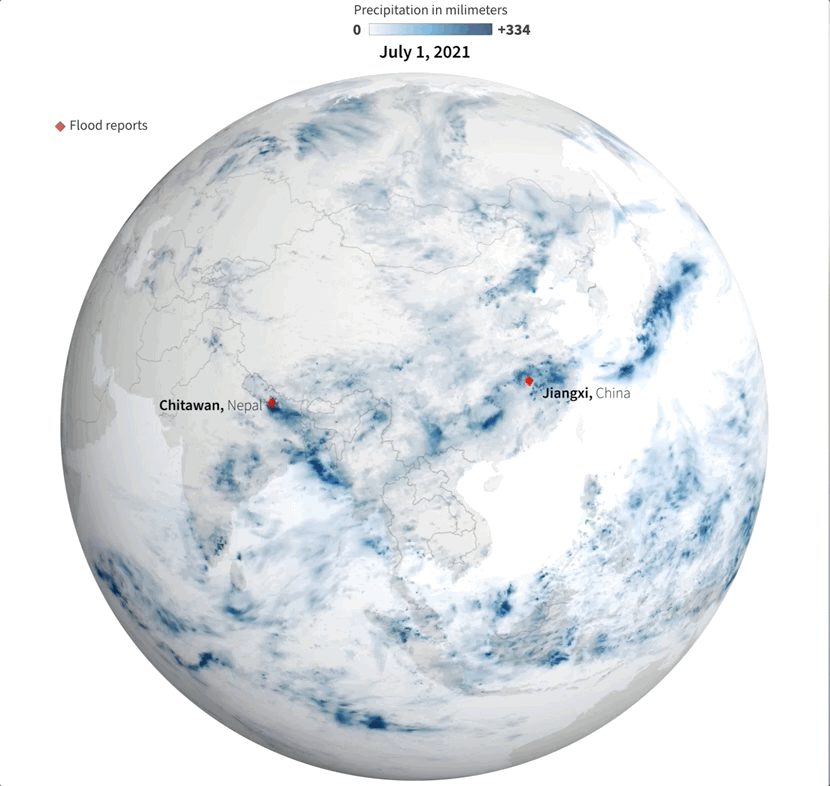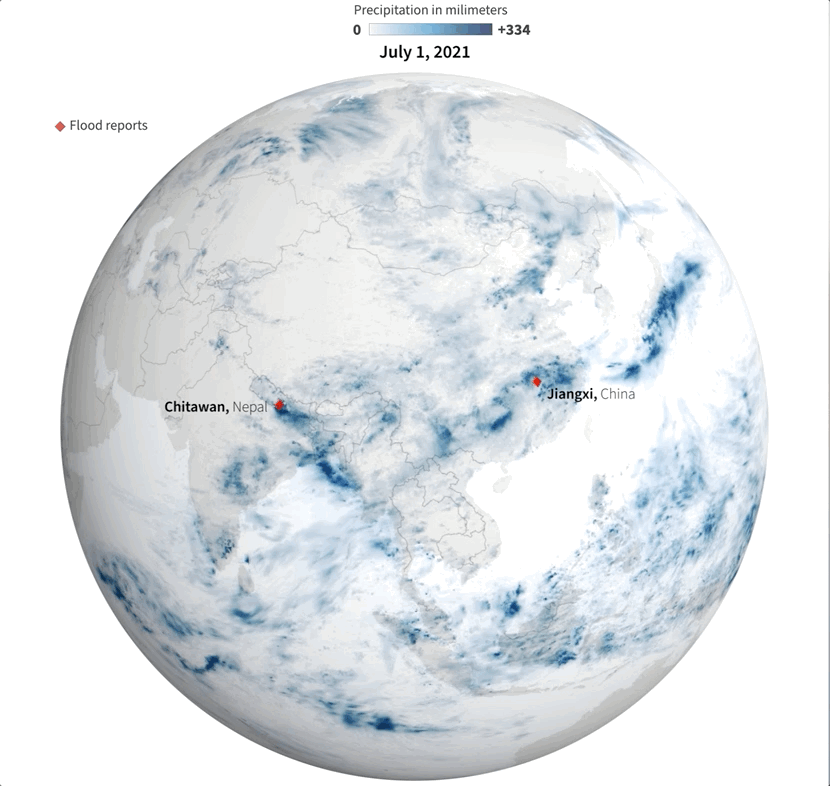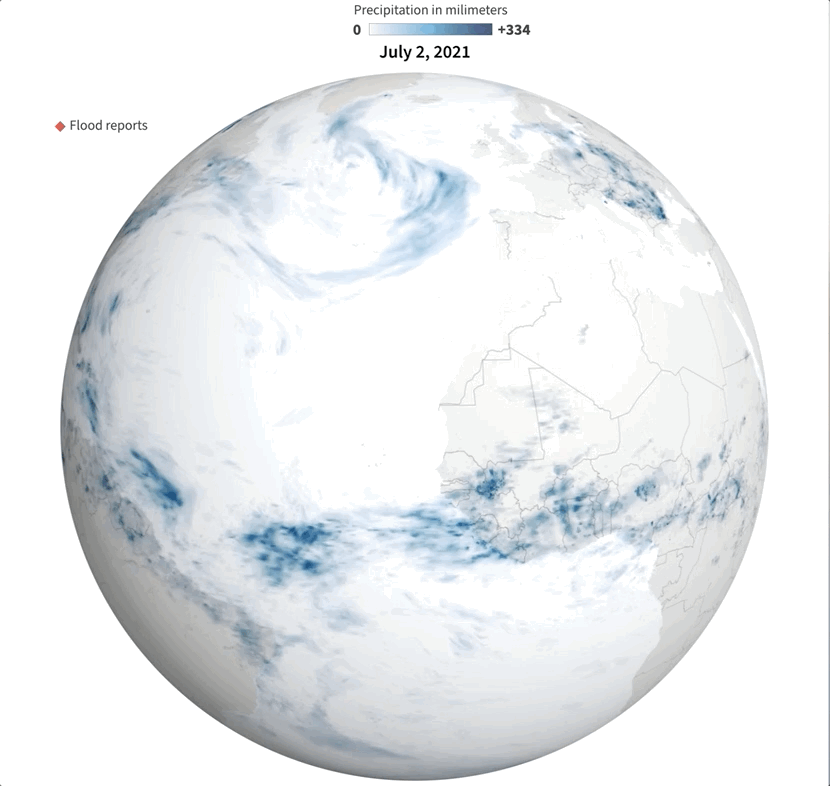
Last July was a crazy month full of flood news all over the world. I remember seeing impressive videos and images of the floods in China and Germany, and digging a little deeper I found many more reports about it from around the world. I tried to put some things together, but time and other projects played a trick and the project became material for #infofails.
Some times taking notes of things isn’t enough for me. One or two illustrator artboards with basic ideas have become the new “office whiteboard sessions” since we started remote work. Quick sketches and some data samples usually help me to organize myself better.
Sampling flood reports and daily precipitation data.
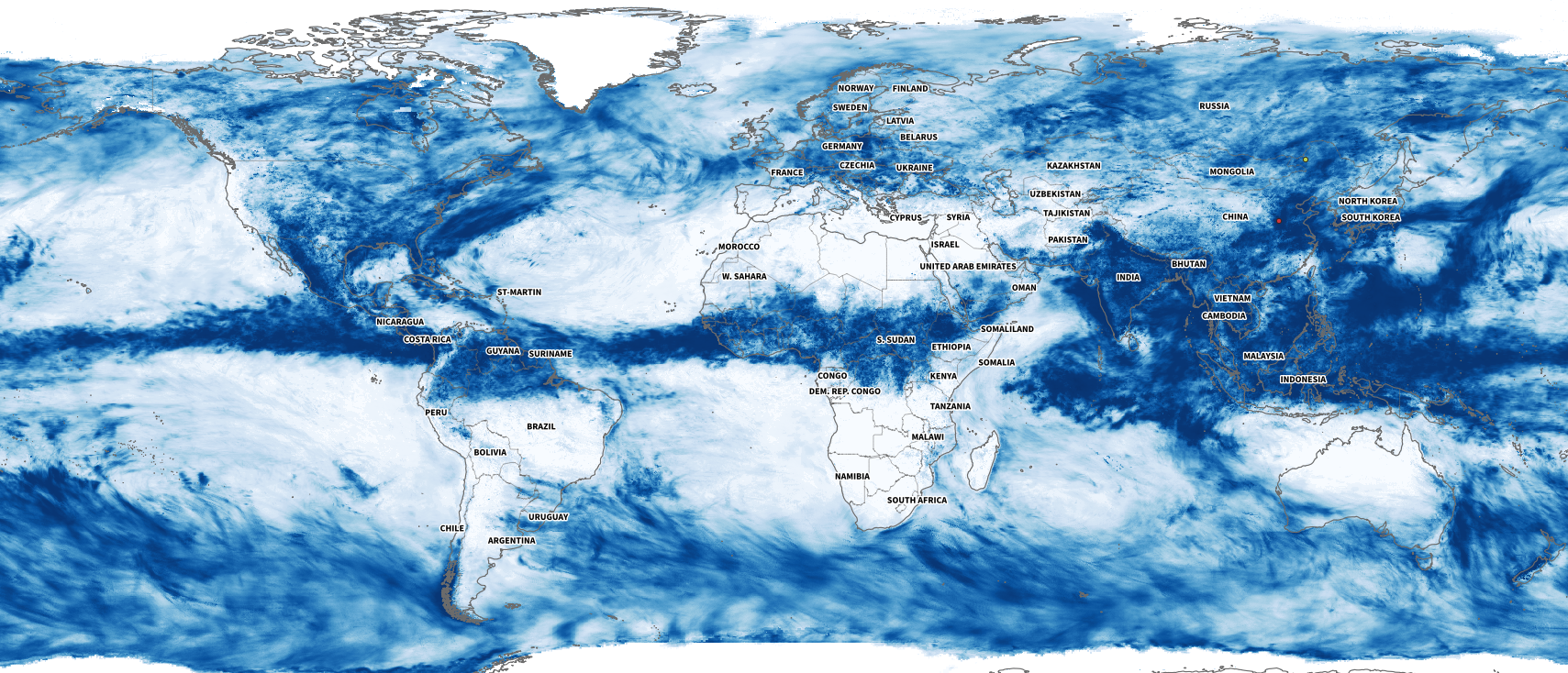
I collected some data from NASA including the PPS and MERRA-2 to visualize precipitation. It was so cool when I saw the data of total rainfall in a month over the planet. Is curious to see how dynamic our planet is isn’t?
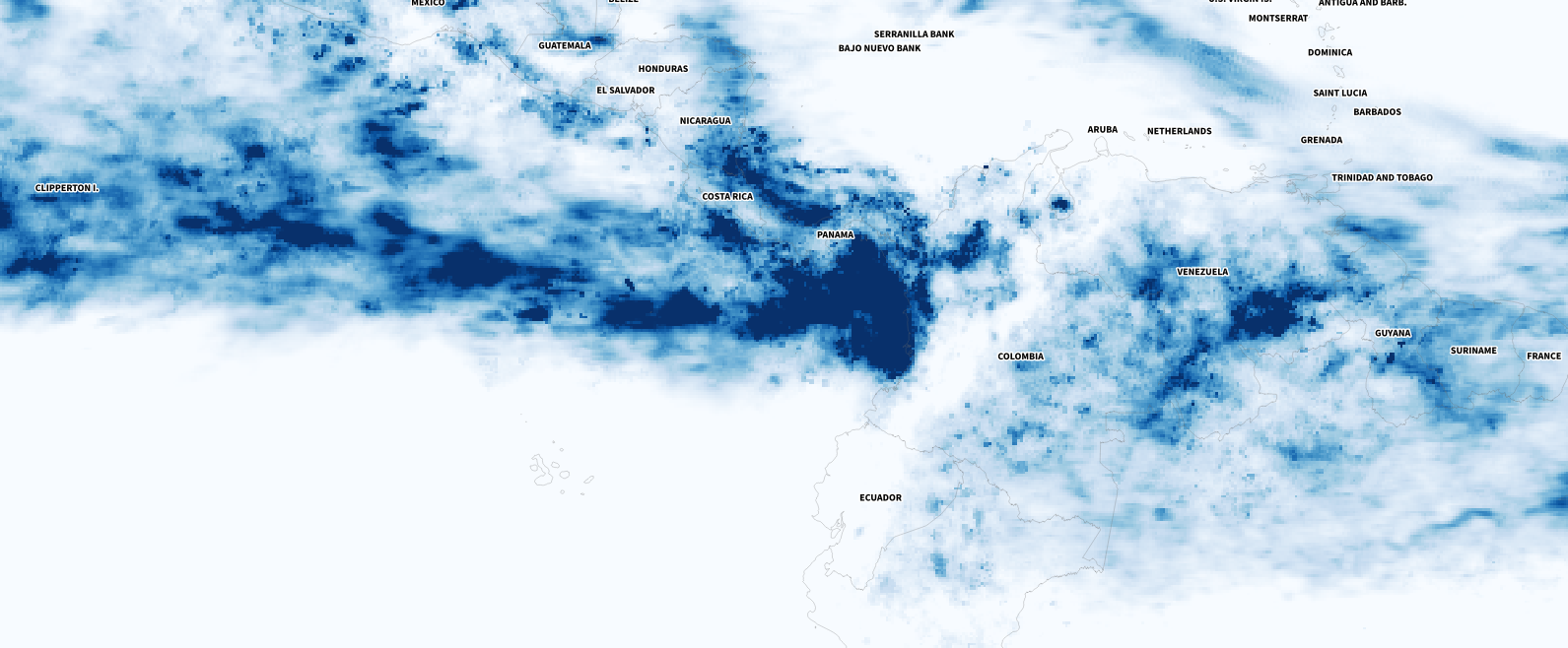
July’s total precipitation. Data by NASA’s Precipitation Processing System (PPS)
Whenever I have a global data set, I always look at how things are for my family and friends in Costa Rica. I remember that in July I had seen videos of flooded areas in Turrialba, a region in the Atlantic region of the country. And yes, the accumulated data showed that intense blue layer near the border with Panama.
Detail of the precipitation data. NASA PPS.
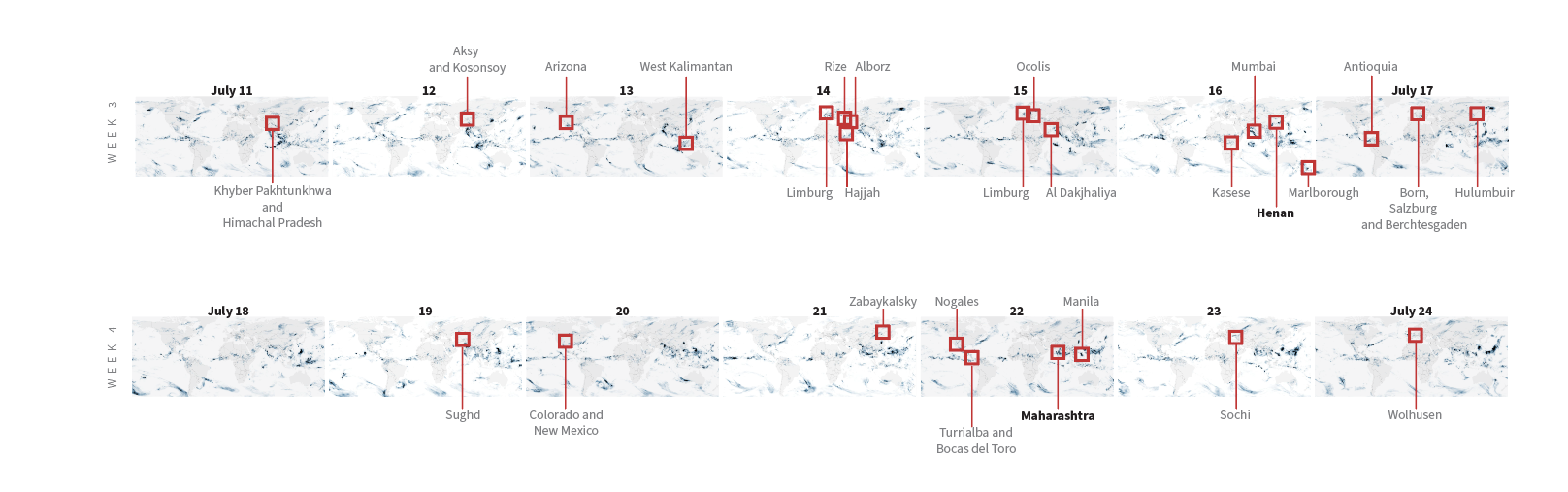
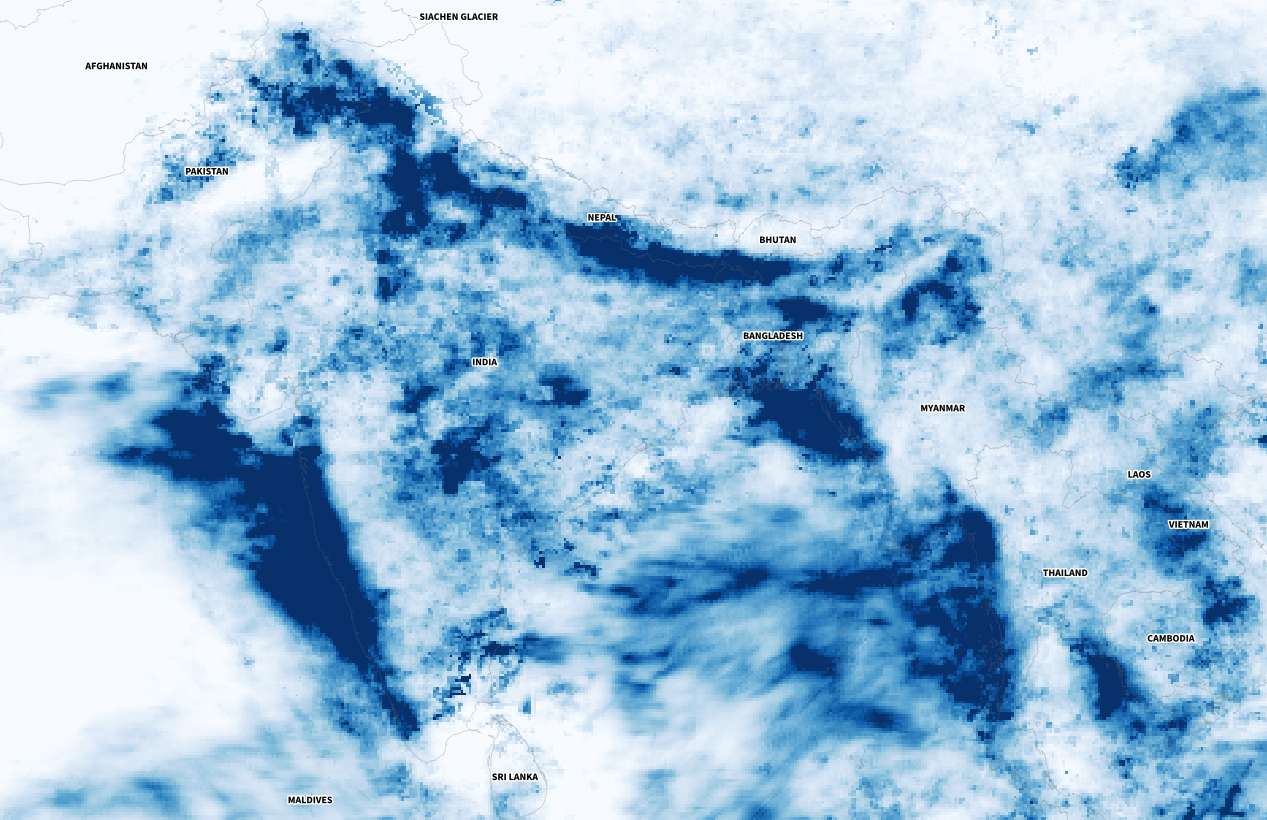
Of course, there were other much worse areas that saw terrifying amounts of precipitation causing dozens of deaths, western India for example was one of those areas. I continued to explore a bit more on the map and checking against the flood reports I found to find points of interest and to highlight later in the story.
Detail of the precipitation data. NASA PPS.
The testing continued
One aspect to consider was how to visualize the data in the end. There was even a 3D spinning globe in the process… As you can imagine it was chaos displaying flood reports, animated rain data, and 3D navigation all at the same time.
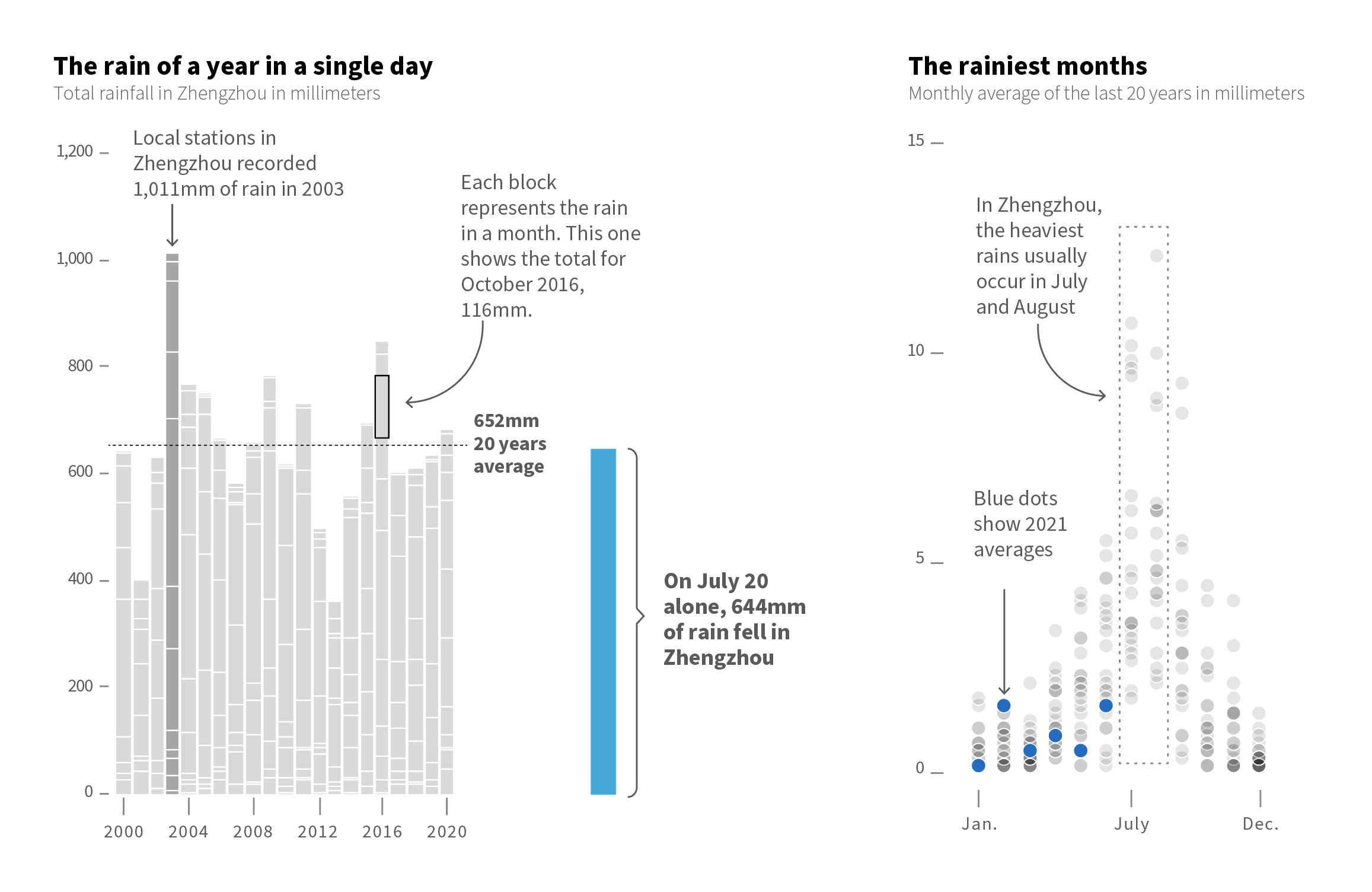
However, one of my favourite pieces was not the maps. There were some small graphics to condense powerful messages had something interesting too. Within them was this simple stacked bar chart where each block showed the total precipitation each month in Zhengzhou, just by putting the amount of water they received on July 20 next to it was really impressive. This is real evidence of how extreme our planet’s climate is becoming.
BTW, there’s also a great graphic from the South China Morning Post friends explaining the huge amount of water that Zhengzhou received over the downpours [ check that story here ]
Extremes
A few years ago I was working on a graphic about extreme temperatures of the earth, it was happening the 2019 polar vortex in the US and at the same time Australia was on 40° C on the other side. In my head, the perfect title was “Earth’s Goldilocks Climate.” It sounds crazy but it is actually very common, our planet is full of those strange contrasts all the time.
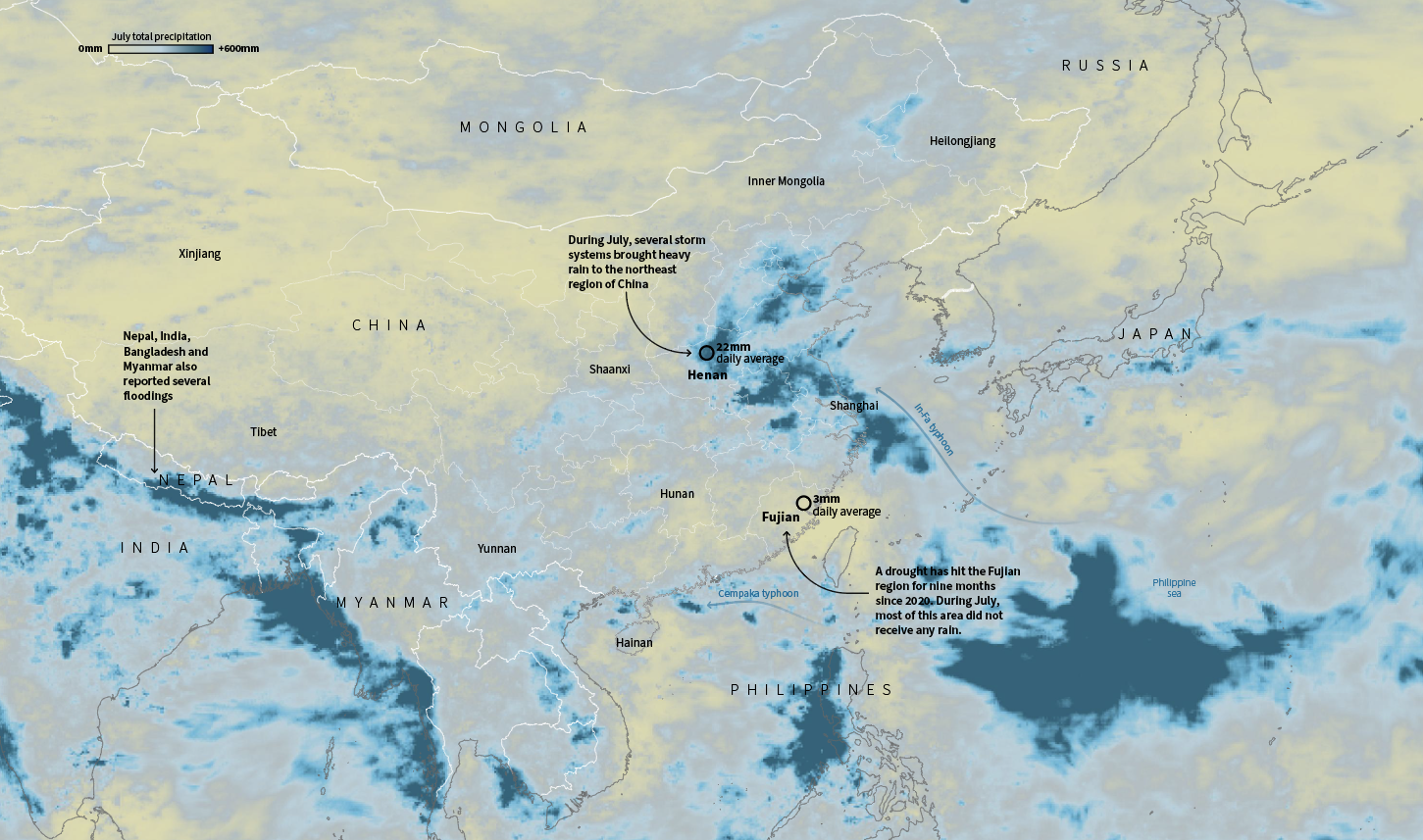
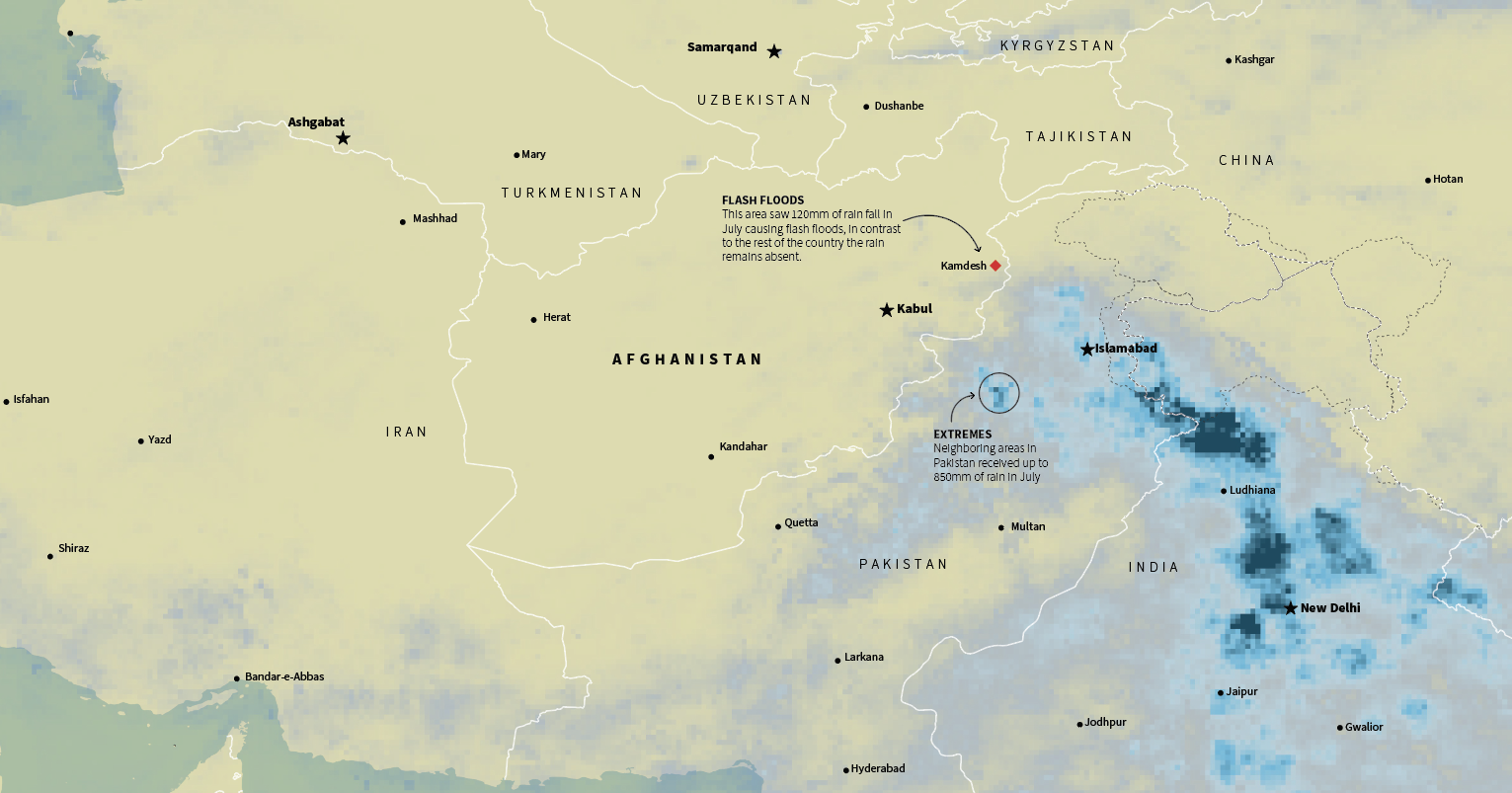
In July China was having its own ‘goldilocks’ event, or kind of, because wasn’t temperature. As enormous amount of water flooded train stations and caused chaos in Henan, south of there a nine-month drought hit Fujian province.
July total precipitation in China. Data by NASA PPS
Similar situations occurred in the Middle East, in Afghanistan a long drought was worsening the already difficult situation of the Afghans. Ironically, extreme rains in the border areas also caused flash flooding, while the country as a whole has not seen any rain for months.
July total precipitation in the Middle East. Data by NASA PPS
NASA’s MODIS/Terra offers also daily and monthly averages of surface temperature. This was some other stuff I was considering for this story. It’s incredible to see how high the temperatures go in the region. There’s also an other cool data set of monthly temp. anomalies here in case you want to explore the world too.
Temperature anomaly for Feb. 2021. Red areas show were the temp. was higher in comparison with the averages of 10 years ago. Afghanistan was about 12C warmer in average according to NASA Earth Observations data. LPDAAC and MODIS.
Anyway, none of these charts, maps or data made it into a true story on Reuters, but it was fun collecting, preparing and sketching ideas for it. And of course, in the end it became an average #infofails story here. Maybe later we will take back again this story, unfortunately extreme weather events are becoming more and more frequent
About #infofails post series: Graphics that are never formally published. Those are maybe tons of versions of a single graphic or some floating concepts and ideas, all part of my creative process. All wrapped up in #infofails, a compilation of my creative process and failures at work.
Did you like #infofails? Have a look to other #infofails 👇
If you’ve seen my #infofails before, you might already know that it’s about the things I create for news and some of the mess in between. Here’s the link [ The Forgotten Olympic Events ] of the project related to this post if you want to have a look first and then come back here to get a better sense of what’s this about.
It’s a bit strange to say that we are about to see the start of the Tokyo 2020 Olympics in the summer of 2021 (if Covid-19 allows the games to go on anyway) but whatever the case, this is one of the most popular events in the world and we couldn’t let it go without a special story.
The idea of doing a story on unusual sports came first in April from my editor Simon Scarr. Later, I started reading old Olympics reports, books and websites to get good references of events that seem a bit unusual in a list of sports/discipline/events from the International Olympic Committee.
Some of the reports and books consulted for the project.
Once we had a good list of curiosities, I started doing some tests for the illustration style. It is not usual to find a solution quickly as I like to try alternatives. However on this particular project the style quickly established, and a few days later I had a lot of illustrations with many of those sporting events to display in the opening of each section.
Top images are part of the concept illustrations, I choose to go with colour as in the top right. The 2 bottom images are part of events the were left out of the story.
I can say that part was relatively easy, the difficult thing was to obtain visual references of the events where you could see how things were prepared for each event, or at least, a detailed written description. I probably spent more time looking for those things rather than writing or sketching.
A reference of the firing range setup for the running deer shooting event
A detail of the rifle shooting section in the project
This project lasted about three months, however I didn’t dedicate myself exclusively to it, but I did spend a few days here and there trying to obtain reliable sources that would explain these singular Olympic events and their rules.
Some references were harder to find than others. For example, the way of placing the wooden birds for the archery events was one of those difficult ones.
I did a drawing of Hubert Van Innis, an Olympic archer who won six medals in the 1900 and 1920 games, but then I found mixed references on how arrows were shoot in the moving bird events, probably my illustration had the wrong pose. I think that’s part of the process, many times I corroborate the references and sources and all makes sense, then something else comes along and the piece becomes a wrong interpretation. So it’s important to check not once but as many times as you can.
Cherry picking
Apart from little difficulties like that one of the moving bird event in archery, the main problem turned out to be too many nice things. It was necessary to take a decision to prevent a never ending story so we took off some events in the list giving priority to the ones with good references and “colourful facts”.
Some events sound very interesting by name, so we chose them for the first list of curious possibilities. A good example of this is the two-handed discus throw, digging a bit further I found that it wasn’t a very creative way of holding the record with both hands as it sounds, but two discus throws, first using the left hand and then the right hand… 😦
Some of the events that I considered within the initial list of Olympic curiosities, but that didn’t make it to the final version. Among them, a 12-hour bike race and army pistol shooting.
It was a very fun story to do, a really enjoyed to read the reports and references. I filled out my mind for a few days of images of how the people saw the games and how different are today.
Here’s a crazy collage with some of the drawings of the project.
Some of the drawings of the project.
A funny project that looks like a huge illustration, but in fact, it has a lot of data behind, a lot of text/data documents, hundreds of old pictures and references of poses developed in 3D. One nice tool that help me a lot to create diverse poses was Magic Poser, this is open web-based 3D environment where you can set a model to any position you need. Here’s the link in case you get in trouble with anatomy or just need some help with pose models.
The folder with the production files of this project. I usually only have 4 or 5 projects on my computer. I guess otherwise it might not move at all 😆
About #infofails post series: Graphics that are never formally published. Those are maybe tons of versions of a single graphic or some floating concepts and ideas, all part of my creative process. All wrapped up in #infofails, a compilation of my creative process and failures at work.
Did you like #infofails? Have a look to other #infofails 👇
Yup, a new crazy and very busy year have started. So, let’s kick off a new season of #infofails from recent months:
Sand mining projects
To be honest, I never thought about sand before this series of projects. However, sand is the planet’s most mined material, some 50 billion tons are extracted from lakes, riverbeds, coastlines and deltas each year, according to the UNEP. All around this topic is fascinating from a visual journalism perspective, the figures are huge and so scary and sad at the same time. –So, ideal for some good stories right?
Early in February, we did this story on how Chinese dredging ships are swarming Taiwan’s Matsu Islands. If you haven’t see it yet, please have a look first and comeback to this post. [ link here too:https://tmsnrt.rs/39OYbAZ ]
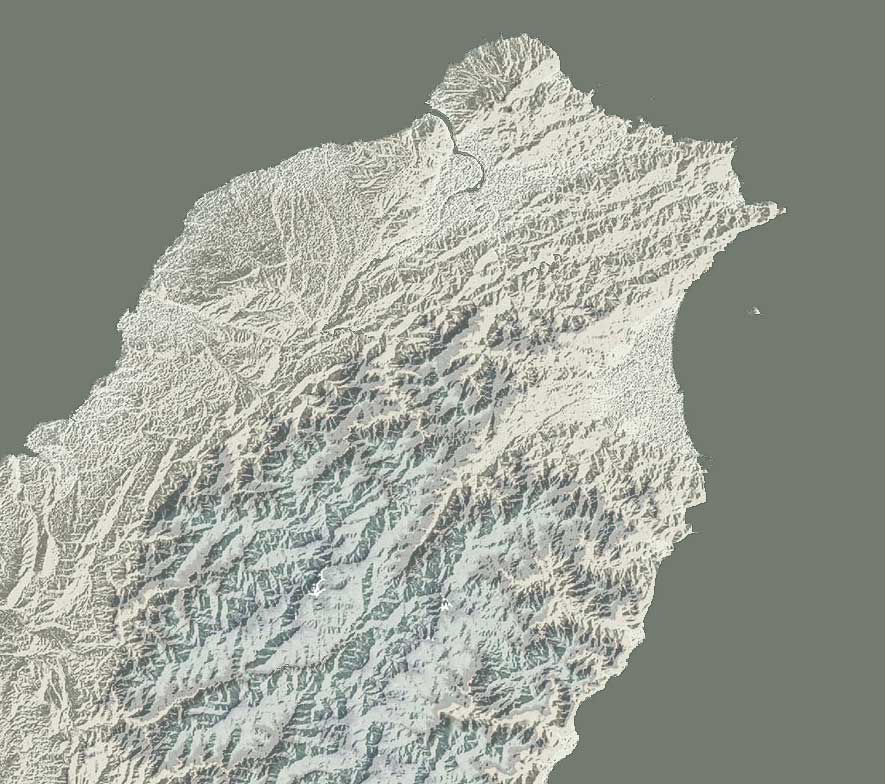
I did some stuff that we didn’t use because we turned into another direction, like the map of Taiwan at the top of this post, I was experimenting a little bit with colour schemes and the way of the relief, below are shown some closer details of Taiwan, Hunan-China, Hong Kong…
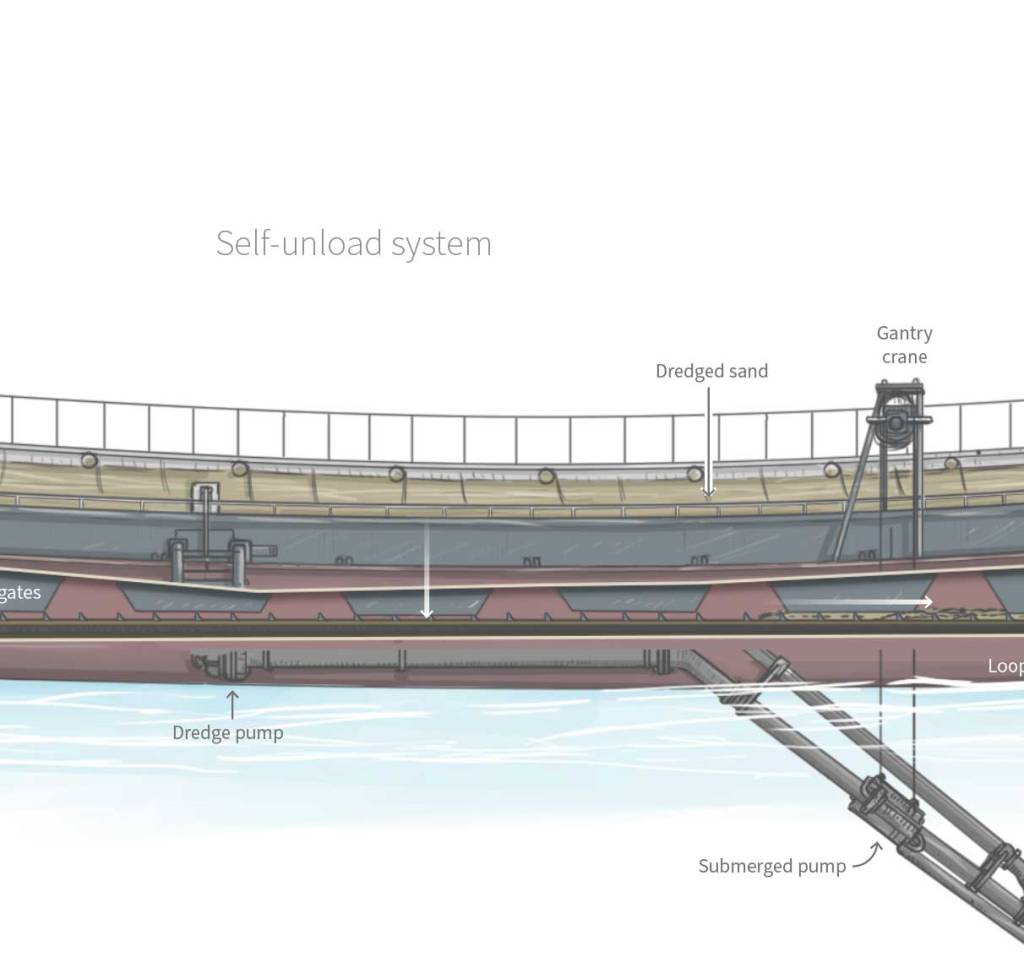
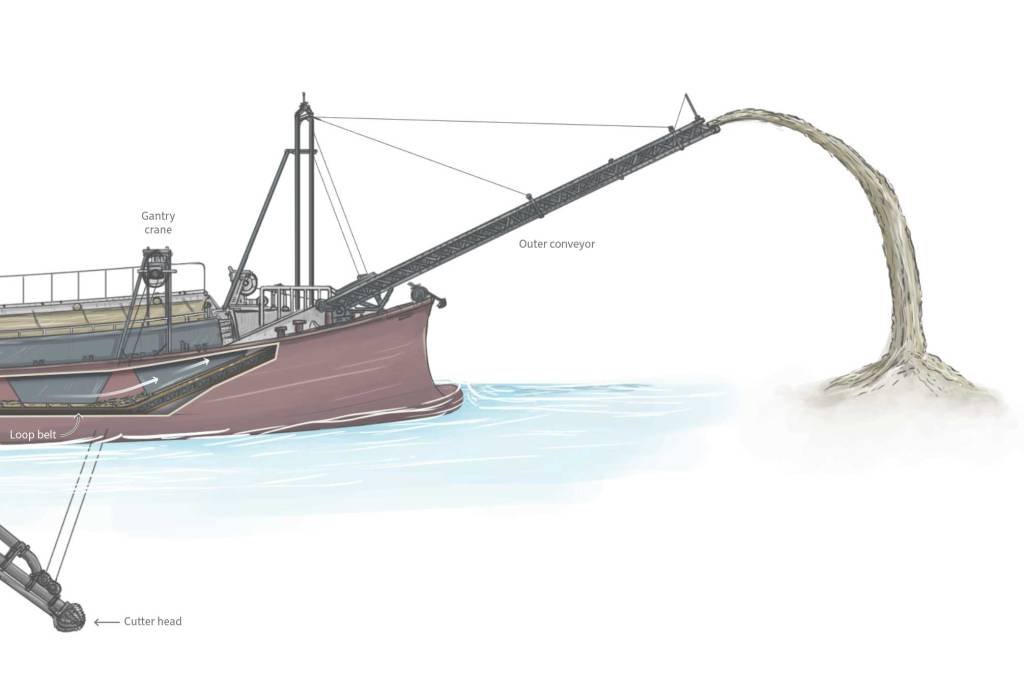
I also spent some time trying to understand how these strange dredge boats dig into the seabed, scoop up the sand, and then spit the material through a conveyor somewhere else. It seems that the Chinese used this type of boat often according to what I could see in many photographs of the Taiwanese islands affected by mining. But at the end we keep it simple with just the outside diagram of the boat as you can see in the page. Here’s a little detail of the inside that I didn’t finish completely:
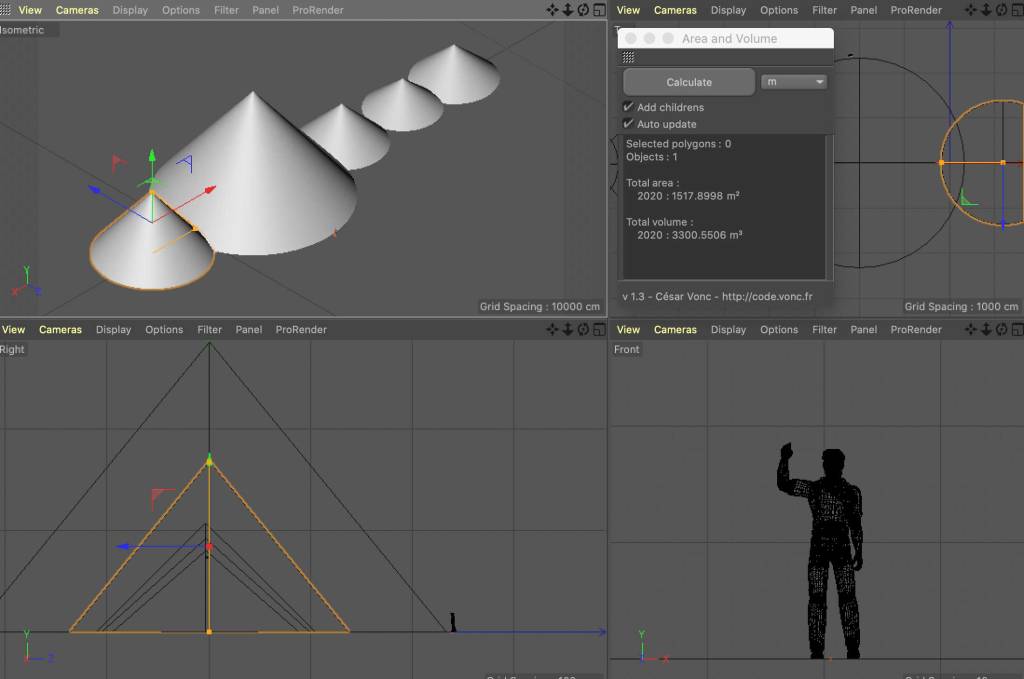
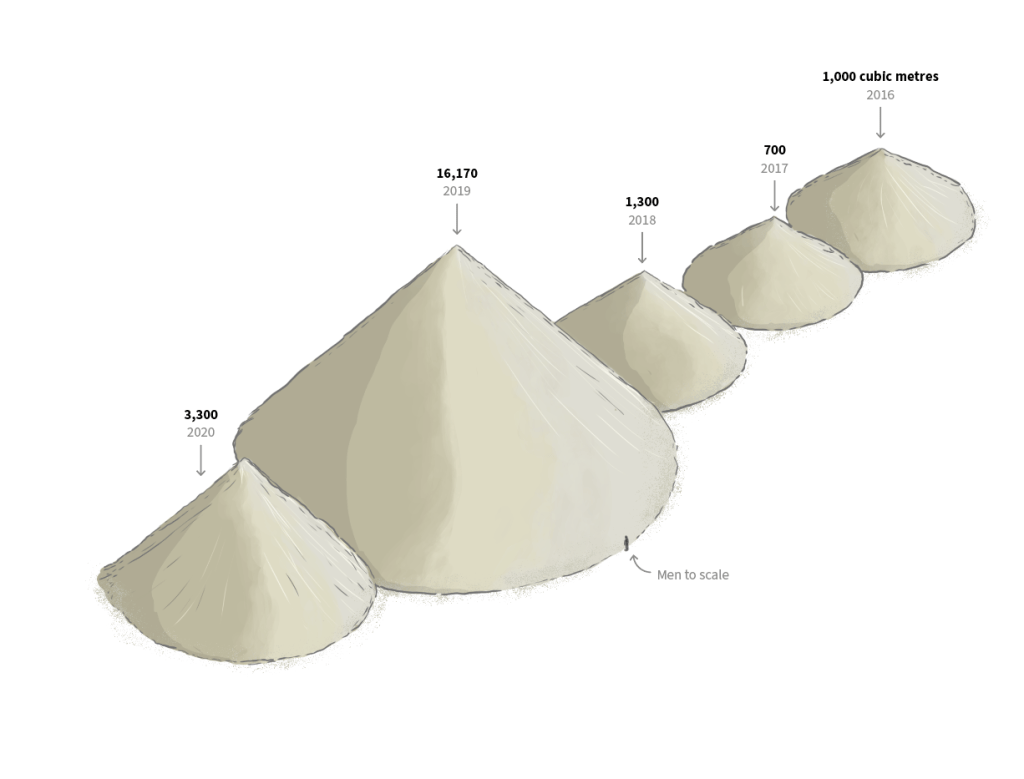
I also got some estimated figures from Taiwan’s Ocean Affairs Council about how much sand the Chinese boats have take over the last five years. In the end we didn’t use it for the story, but the idea was to model piles with the same estimated volume and use the same style as the sand dredger above alongside a 2-meter man to give a better understanding of the amount of sand extracted. .
(software screenshot) Cinema 4D model to calculate the volume of each pile in cubic meters. | (illustration) Piles sketch based in the render with labels of the Taiwanese estimates of sand taken since 2016.
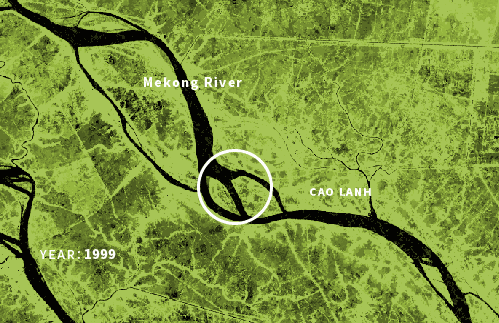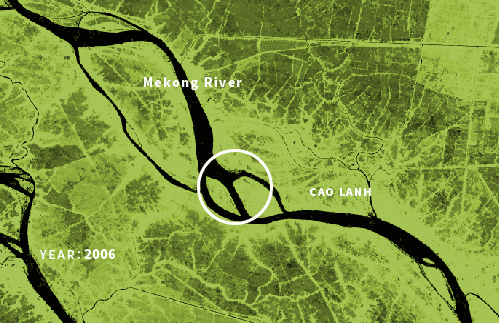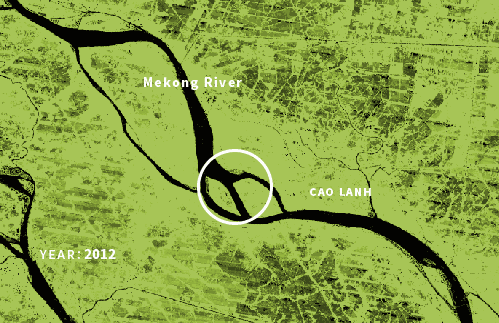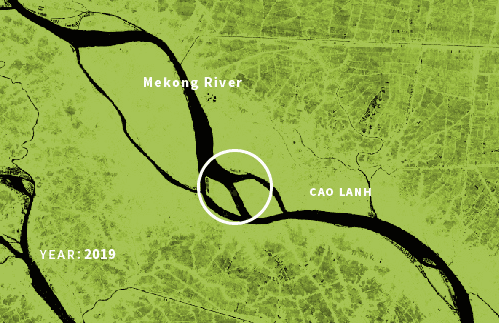
Some nice data I also was looking into was the GLAD ( Global Surface Water Dynamics ) those data sets are based in Landsat 5, 7, and 8 scenes, and they are so cool but didn’t use for the project. In that DB, you can see how rivers and water bodies in general have changed their shapes since 1999. I was looking at the Mekong river, but the data coverage is global and there are some really nice parts like this section of in Bangladesh:
(Whiteish image) 999-2020 surface water changes near Padma River, Bangladesh. Data composite by GLAD web interface. | (Greenish image) Changes in the Mekong River, near the An Giang province,Vietnam. Based on GLAD data.
In fact, I played a lot with these sand projects. From particles to animations, maps, illustrations … I made some fading castles for the top image before it ended up in a city made of sand as shown now. I made sand elephants, particles to see how different the grains are … LOTS of exploration to better understand the subject and I can say that anyone can spend years making visual stories about sand.
Random screenshots of Cinema 4D models related to sand projects.
Other projects
I’ll keep this short since I already wrote down a lot about sand, let’s consider this tiny section as a bonus track 😆
Also in early January, we saw the story of the Chinese miners trapped inside a deep mine, it may looks like a huge simple illustration, but it has a lot of research behind to make it as much accurate as a breaking news story can be.
About 600 people are involved in the rescue of miners trapped outside Yantai, China, after an explosion that occurred on Jan. 10 https://t.co/oMK4vAxUpG via @ReutersGraphics
Illustrations sometimes can be way much more complicated than dataviz graphics I think. That, because you can’t argue with data, or print your own perceptions into something that it’s already simplified to dots and lines. Let’s make a little parenthesis here:
The illustrated graphics are more humanistic yes, but also complicated because you cannot detach yourself from those same parts that connect you with the information, those that you use to "humanise the information". I mean, you can't control what the people will see there, because it opens a wide range of interpretation. Not like strait forward dataviz isn't? Well, maybe not even in dataviz, everything have exceptions. Just look at [ this ] tweets by Francis Gagnon that sparked a lot of opinions in the visual journalism community about how cold and inhuman are "dots" representing people in a NYT graphic in the print front page.
Ok, turning back to #infofails, in January also I worked in the Sriwijaya crash story, a straightforward breaking news story. The opening image saw some versions as we tried to tackle a sensitive topic and not give the wrong message to the readers at the very top of the story.
An alternative version of cover for the Sriwijaya Air Flight SJ182 story. [ LINK HERE ]
Some times I just want to run away from noisy things, have a look to the most basic and elemental thing in the visual I’m creating. So then I can go and add little clues for the eye. Doing that I think, we can find what’s needed to be highlighted, we can also understand what we know, but maybe not the reader isn’t understanding at the first instance by looking the graphic.
A map of Antarctica’s icebergs, just icebergs. Not land, sea or labels. Based on data from BYU Antarctic Iceberg Database
About #infofails post series: I keep my beta graphics, those that never go public… Maybe they are tons of versions of a graphic or just a few concepts, part of my creative process. So, where all those things go? well, ends-up in #infofails –a collection of my fails at work.
Did you like #infofails? Have a look to other #infofails Chapters here:
2020 kicked off with record-breaking wildfires in Australia, the hatching a global pandemic, and later the a new wildfires season turning into ashes thousands of sqkm of the U.S. West Coast, then Trump again… you know all that right?
In the middle of all that craziness, we were juggling to cover the events with visual stories. As usual, I did a little more than necessary in order to explore and get details relevant to our stories… and well, not all of them worked out…
Where there is fire, there is smoke
Some events on our planet reach sufficient dimensions to be easily seen from space, wildfires are one of them.
Mercator projected snapshot of organic carbon data on September 16th, 2020. Data from NASA-GMAO
I had work with GMAO data many times before, it’s a good source to see a model of aerosols and other specific data on a large scale, works very well for continental areas, not too much for a closer zoom like country level.
Anyway, the idea of this. visualisation was very clear, it was about to show the large dimension of the smoke caused by the wildfires in the US. West Coast.
One by one in QGIS, I did a series of renderings like the one shown above with data between June and mid-September (around 100 days), which is probably not too much, but the data is collected every 3 hours so I manually processed about 400 files to get a smooth animation.
Animation test v1.
To get control of the style without coming again to QGIS, I did the series of data only, a layer with the country borders, a layer with labels and so on… I also did one version with the same idea but in a globe.
Style test. v4.
I often try different versions of my graphics, On my team here at Reuters, we often joke that until we get to the twentieth version we won’t be close to finishing … Although in some cases that joke does come true.
The final version ended up looking a bit different. I controlled the final style in Illustrator, Photoshop and After Effects.
Final version. ( v.11 )
There are many more pieces in that story, including a really cool cutaway of the smoke made by my teammate Manas Sharma with data from NASA’s Calipso mission. You can have a look to the full story here: https://tmsnrt.rs/3nkkOkX.
But the wildfires continued to break historical records and turning the city’s skies orange-red. There were many other stories on that tragedy waiting to be told, even though the stories of the covid-19 did not stop harassing us either.
An aircraft swarm
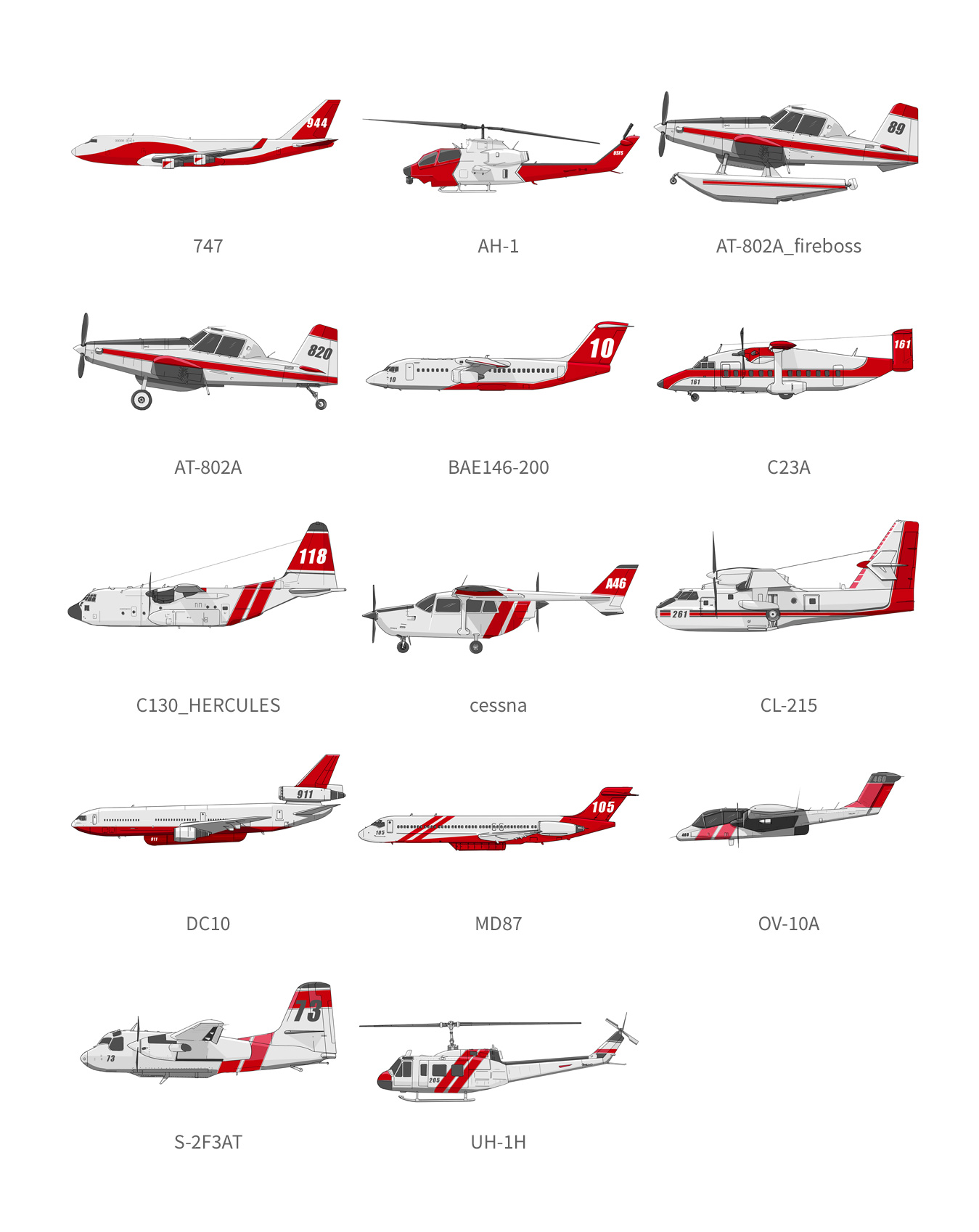
OV-10 “Bronco” sketch test for the Cal Fire aircraft story.
Air attack was one of those stories we worked on in the middle of this year, the main idea was to show the impressive deployment and coordination of planes to deal with the fires in California. Just doing the planes was very enthusiastic, the main issue was how to pick the right ones.
Cal-Fire has on hand an extensive fleet of planes, tankers and helicopters, some in heavy operation, others less so. However, the flight and route logs from FlightRadar24 gave us an outlet to filter the aircraft.
Cal Fire aircraft sketches for the story.
You may have noticed some airplanes in the image above that aren’t in the final story. The AT-802A were used to guide tankers in the old days, they are probably still in use elsewhere, I think you can see them in the Pixar movie “Planes”.
That was one of the “unnecessary resources” that I created, thinking that it might have been nice to show how things have evolved over the years, but it was not the case. You can read the story through the following link: https://tmsnrt.rs/2Iy2K7W
Wine and ashes
There’s one thing you should know about me: I love wine.
I usually work colour at the end. More versions to test and try keeping outlines or light-shadows intact.
Most of the stories I’ve made in the last year or two are sad, some about environmental disasters, people in danger, dying, or losing everything.
Like many, this story came with some mixed feelings. I think it was the first time that I had the opportunity to do something about wine, and it involved the destruction of hundreds of vineyards.
Although I really enjoy to do reporting, create a map, draw a diagram, or write a story draft, those same stories always bring me a strange mix of joy in doing my job and the sadness of understanding the dimensions of a problem or event. I’m not complaining, I keep my job at the office, but it’s curious I guess.
Not matter how much time I can have, there’s always one more thing I’ll like to explore. Nice thing is you can save the idea in the bucket for next time. And the fires coverage wasn’t an exception.
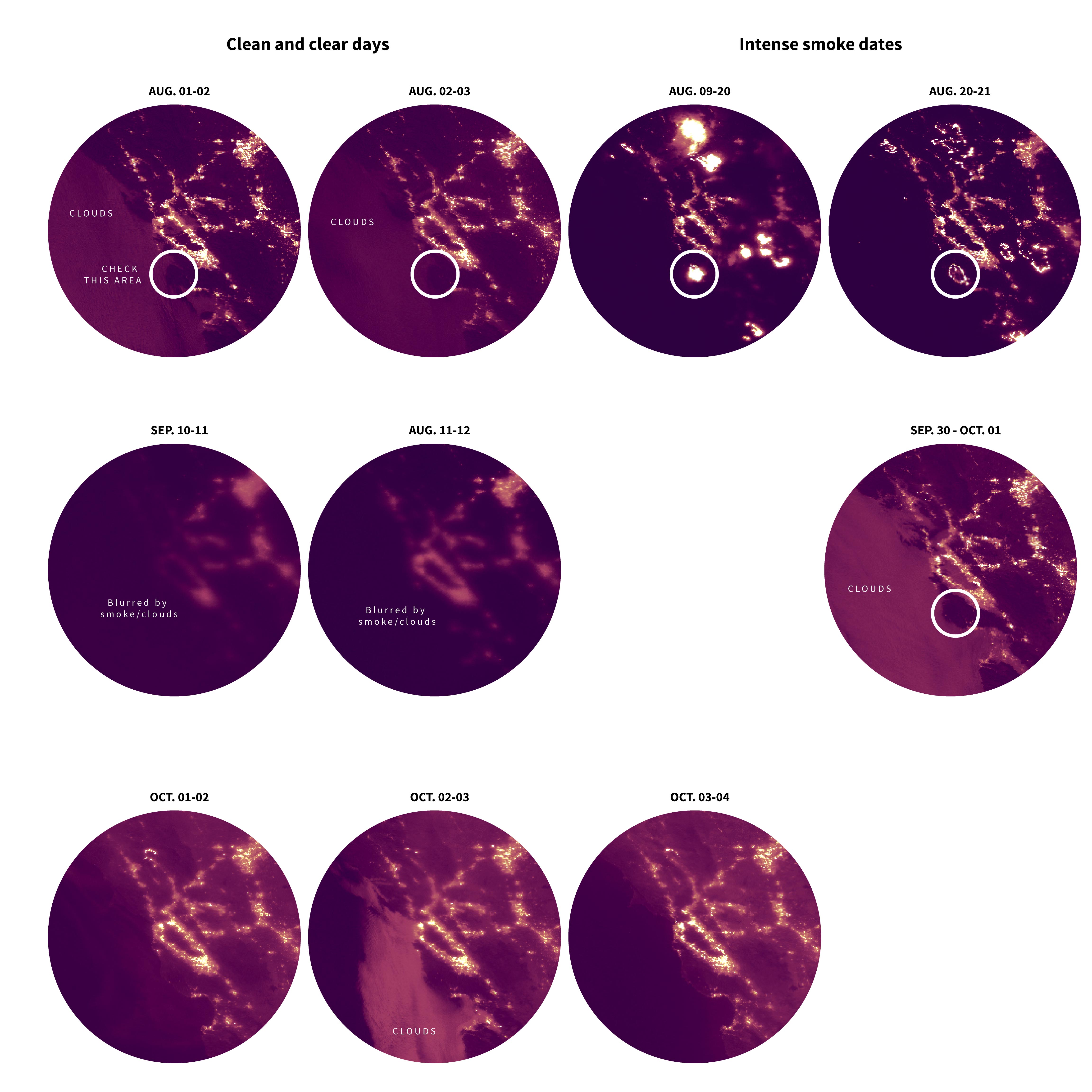
Screenshot of the VIRS brightness data over California. Night time Aug. 03, 2020.
Around mid year, I was exploring at VIIRS/NPP data, this data contains 26 data sets including radiance sensors, shortwave IR radiance, earth’s brightness and temperatures etc.
That data can give you a daily quick look of lights and temperatures of the planet’s surface, of course if clouds play nice and go away from your interest area.
After downloading the data for a few days in the area, I noticed some bright areas that turned on and off depending on the day, probably fires that were seen burning from space at night.
The lights were so intense that you can easily mistake them for city lights. Check the white circles bellow:
About #infofails post series: I keep my beta graphics, those that never go public… Maybe they are tons of versions of a graphic or just a few concepts, part of my creative process. So, where all those things go? well, ends-up in #infofails –a collection of my fails at work.
Did you like #infofails? Have a look to other #infofails Chapters here: